 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood Intentions: Adaptive Parameter Servers via Intent Signaling
Paper and Code
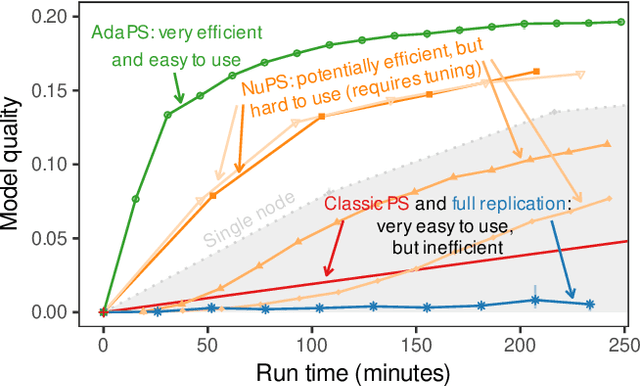


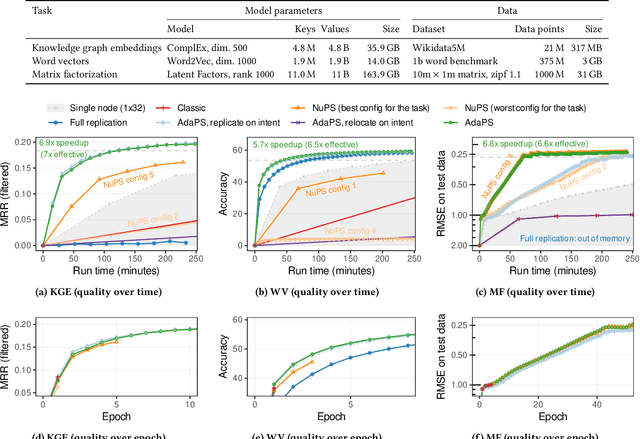
Parameter servers (PSs) ease the implementation of distributed training for large machine learning (ML) tasks by providing primitives for shared parameter access. Especially for ML tasks that access parameters sparsely, PSs can achieve high efficiency and scalability. To do so, they employ a number of techniques -- such as replication or relocation -- to reduce communication cost and/or latency of parameter accesses. A suitable choice and parameterization of these techniques is crucial to realize these gains, however. Unfortunately, such choices depend on the task, the workload, and even individual parameters, they often require expensive upfront experimentation, and they are susceptible to workload changes. In this paper, we explore whether PSs can automatically adapt to the workload without any prior tuning. Our goals are to improve usability and to maintain (or even improve) efficiency. We propose (i) a novel intent signaling mechanism that acts as an enabler for adaptivity and naturally integrates into ML tasks, and (ii) a fully adaptive, zero-tuning PS called AdaPS based on this mechanism. Our experimental evaluation suggests that automatic adaptation to the workload is indeed possible: AdaPS matched or outperformed state-of-the-art PSs out of the box.