 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving VAE-based Representation Learning
Paper and Code
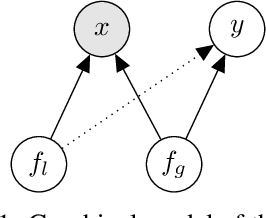

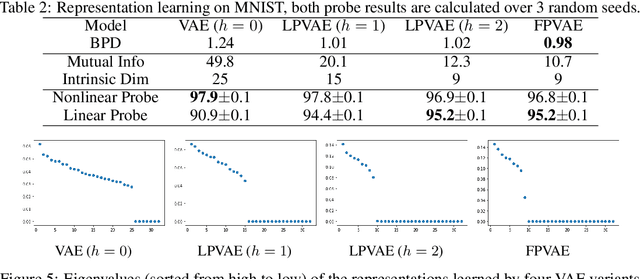
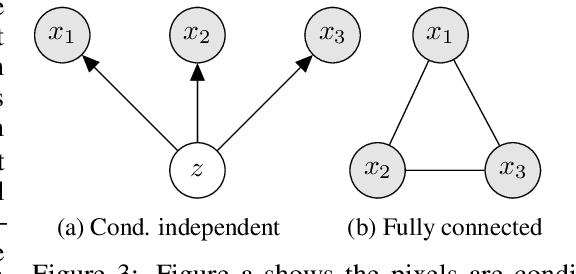
Latent variable models like the Variational Auto-Encoder (VAE) are commonly used to learn representations of images. However, for downstream tasks like semantic classification, the representations learned by VAE are less competitive than other non-latent variable models. This has led to some speculations that latent variable models may be fundamentally unsuitable for representation learning. In this work, we study what properties are required for good representations and how different VAE structure choices could affect the learned properties. We show that by using a decoder that prefers to learn local features, the remaining global features can be well captured by the latent, which significantly improves performance of a downstream classification task. We further apply the proposed model to semi-supervised learning tasks and demonstrate improvements in data efficiency.