 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual-T0: Progressively Instructing 50+ Tasks to Language Models Without Forgetting
Paper and Code

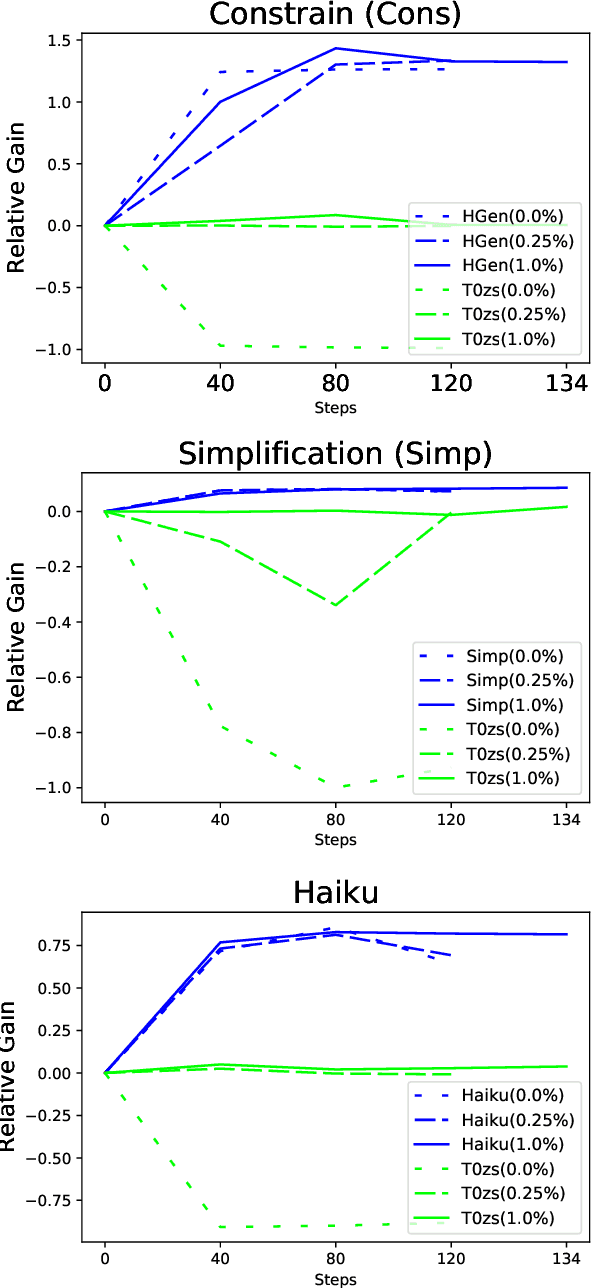
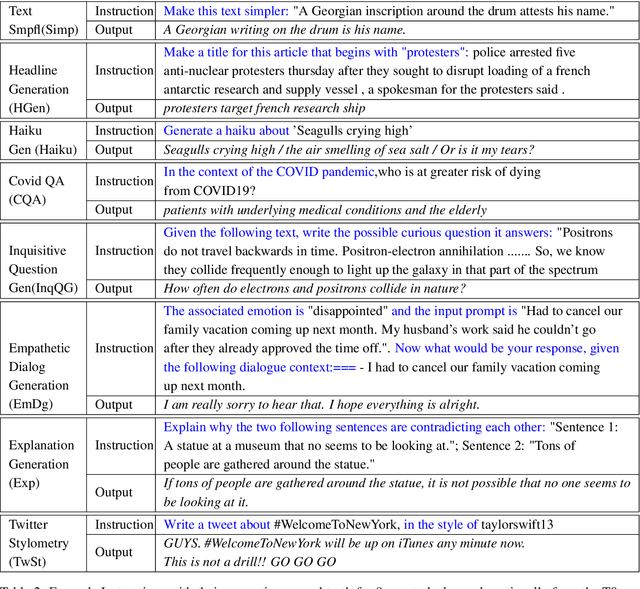
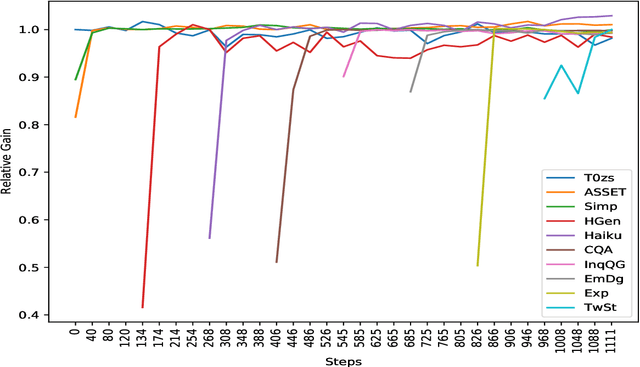
Recent work on large language models relies on the intuition that most natural language processing tasks can be described via natural language instructions. Language models trained on these instructions show strong zero-shot performance on several standard datasets. However, these models even though impressive still perform poorly on a wide range of tasks outside of their respective training and evaluation sets. To address this limitation, we argue that a model should be able to keep extending its knowledge and abilities, without forgetting previous skills. In spite of the limited success of Continual Learning we show that Language Models can be continual learners. We empirically investigate the reason for this success and conclude that Continual Learning emerges from self-supervision pre-training. Our resulting model Continual-T0 (CT0) is able to learn diverse new tasks, while still maintaining good performance on previous tasks, spanning remarkably through 70 datasets in total. Finally, we show that CT0 is able to combine instructions in ways it was never trained for, demonstrating some compositionality.