 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTDT: Teaching Detectors to Track without Fully Annotated Videos
Paper and Code
May 11, 2022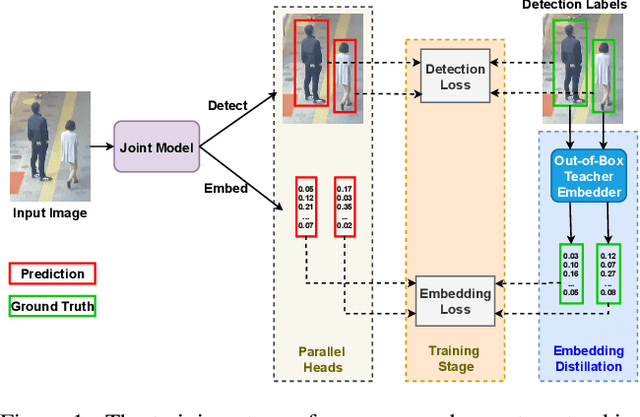

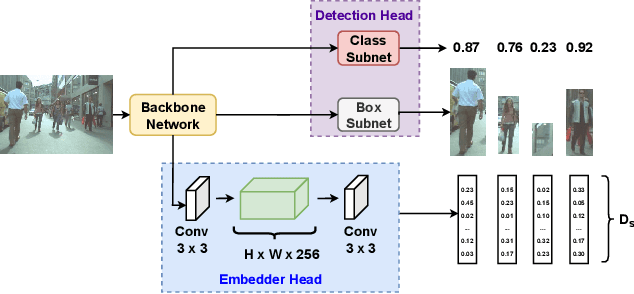
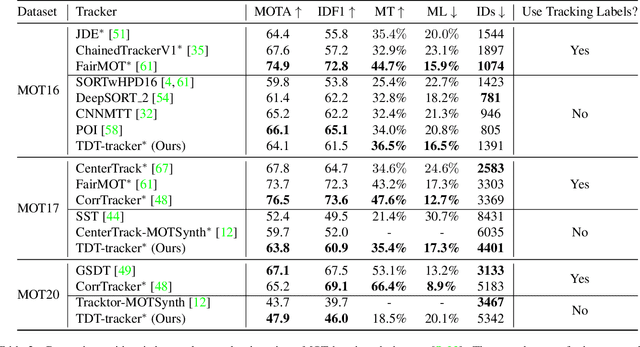
Recently, one-stage trackers that use a joint model to predict both detections and appearance embeddings in one forward pass received much attention and achieved state-of-the-art results on the Multi-Object Tracking (MOT) benchmarks. However, their success depends on the availability of videos that are fully annotated with tracking data, which is expensive and hard to obtain. This can limit the model generalization. In comparison, the two-stage approach, which performs detection and embedding separately, is slower but easier to train as their data are easier to annotate. We propose to combine the best of the two worlds through a data distillation approach. Specifically, we use a teacher embedder, trained on Re-ID datasets, to generate pseudo appearance embedding labels for the detection datasets. Then, we use the augmented dataset to train a detector that is also capable of regressing these pseudo-embeddings in a fully-convolutional fashion. Our proposed one-stage solution matches the two-stage counterpart in quality but is 3 times faster. Even though the teacher embedder has not seen any tracking data during training, our proposed tracker achieves competitive performance with some popular trackers (e.g. JDE) trained with fully labeled tracking data.