 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Eye: On the Limits of Textual Screen Peeking via Eyeglass Reflections in Video Conferencing
Paper and Code


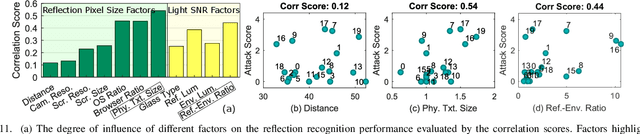

Personal video conferencing has become the new norm after COVID-19 caused a seismic shift from in-person meetings and phone calls to video conferencing for daily communications and sensitive business. Video leaks participants' on-screen information because eyeglasses and other reflective objects unwittingly expose partial screen contents. Using mathematical modeling and human subjects experiments, this research explores the extent to which emerging webcams might leak recognizable textual information gleamed from eyeglass reflections captured by webcams. The primary goal of our work is to measure, compute, and predict the factors, limits, and thresholds of recognizability as webcam technology evolves in the future. Our work explores and characterizes the viable threat models based on optical attacks using multi-frame super resolution techniques on sequences of video frames. Our experimental results and models show it is possible to reconstruct and recognize on-screen text with a height as small as 10 mm with a 720p webcam. We further apply this threat model to web textual content with varying attacker capabilities to find thresholds at which text becomes recognizable. Our user study with 20 participants suggests present-day 720p webcams are sufficient for adversaries to reconstruct textual content on big-font websites. Our models further show that the evolution toward 4K cameras will tip the threshold of text leakage to reconstruction of most header texts on popular websites. Our research proposes near-term mitigations, and justifies the importance of following the principle of least privilege for long-term defense against this attack. For privacy-sensitive scenarios, it's further recommended to develop technologies that blur all objects by default, then only unblur what is absolutely necessary to facilitate natural-looking conversations.