 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCR Synthetic Benchmark Dataset for Indic Languages
Paper and Code
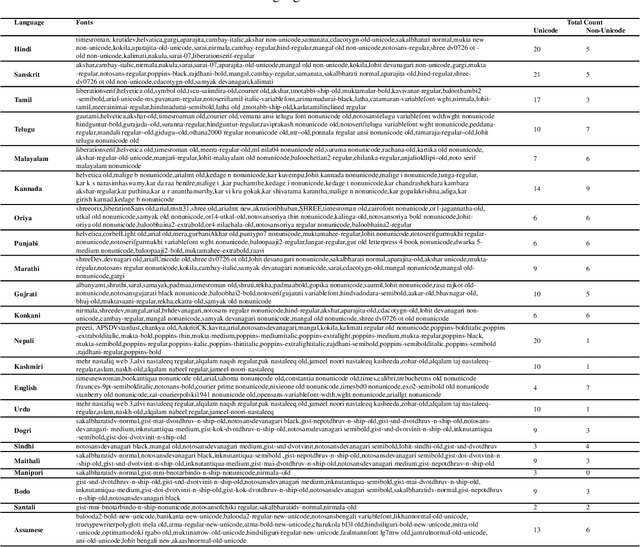
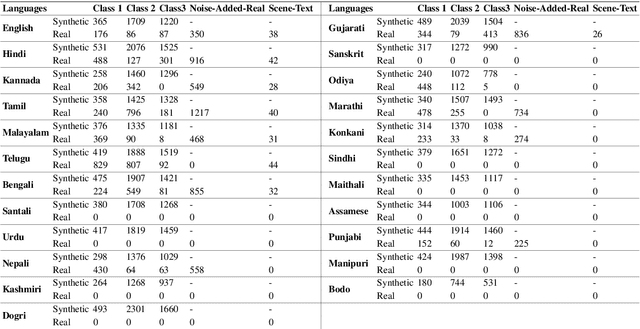
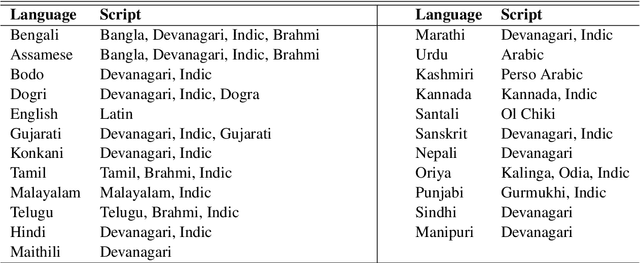
We present the largest publicly available synthetic OCR benchmark dataset for Indic languages. The collection contains a total of 90k images and their ground truth for 23 Indic languages. OCR model validation in Indic languages require a good amount of diverse data to be processed in order to create a robust and reliable model. Generating such a huge amount of data would be difficult otherwise but with synthetic data, it becomes far easier. It can be of great importance to fields like Computer Vision or Image Processing where once an initial synthetic data is developed, model creation becomes easier. Generating synthetic data comes with the flexibility to adjust its nature and environment as and when required in order to improve the performance of the model. Accuracy for labeled real-time data is sometimes quite expensive while accuracy for synthetic data can be easily achieved with a good score.