 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Recognition in the Wild
Paper and Code
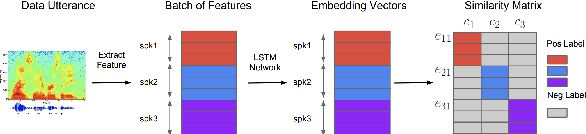

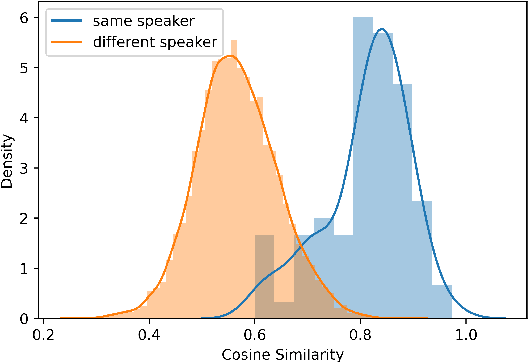
In this paper, we propose a pipeline to find the number of speakers, as well as audios belonging to each of these now identified speakers in a source of audio data where number of speakers or speaker labels are not known a priori. We used this approach as a part of our Data Preparation pipeline for Speech Recognition in Indic Languages (https://github.com/Open-Speech-EkStep/vakyansh-wav2vec2-experimentation). To understand and evaluate the accuracy of our proposed pipeline, we introduce two metrics: Cluster Purity, and Cluster Uniqueness. Cluster Purity quantifies how "pure" a cluster is. Cluster Uniqueness, on the other hand, quantifies what percentage of clusters belong only to a single dominant speaker. We discuss more on these metrics in section \ref{sec:metrics}. Since we develop this utility to aid us in identifying data based on speaker IDs before training an Automatic Speech Recognition (ASR) model, and since most of this data takes considerable effort to scrape, we also conclude that 98\% of data gets mapped to the top 80\% of clusters (computed by removing any clusters with less than a fixed number of utterances -- we do this to get rid of some very small clusters and use this threshold as 30), in the test set chosen.