 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Driven Separation of Arbitrary Sounds
Paper and Code
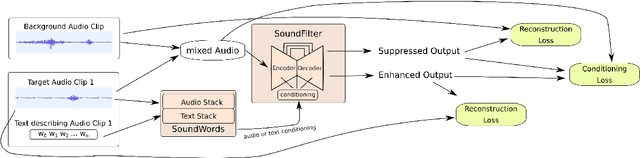

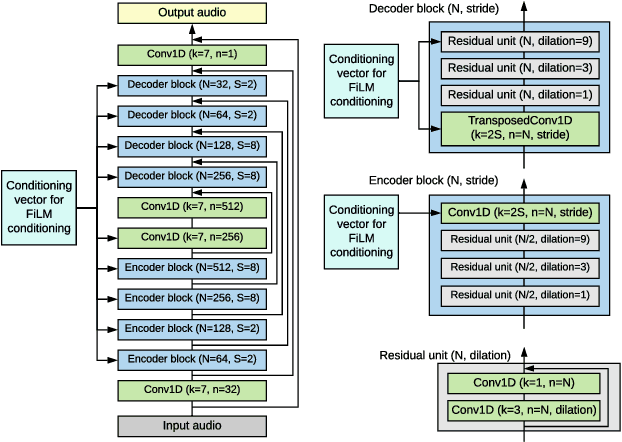
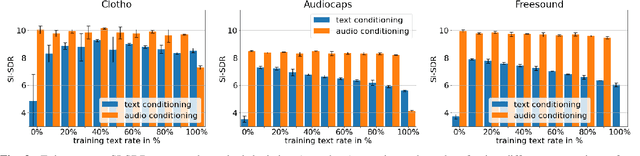
We propose a method of separating a desired sound source from a single-channel mixture, based on either a textual description or a short audio sample of the target source. This is achieved by combining two distinct models. The first model, SoundWords, is trained to jointly embed both an audio clip and its textual description to the same embedding in a shared representation. The second model, SoundFilter, takes a mixed source audio clip as an input and separates it based on a conditioning vector from the shared text-audio representation defined by SoundWords, making the model agnostic to the conditioning modality. Evaluating on multiple datasets, we show that our approach can achieve an SI-SDR of 9.1 dB for mixtures of two arbitrary sounds when conditioned on text and 10.1 dB when conditioned on audio. We also show that SoundWords is effective at learning co-embeddings and that our multi-modal training approach improves the performance of SoundFilter.