 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame Author or Just Same Topic? Towards Content-Independent Style Representations
Paper and Code
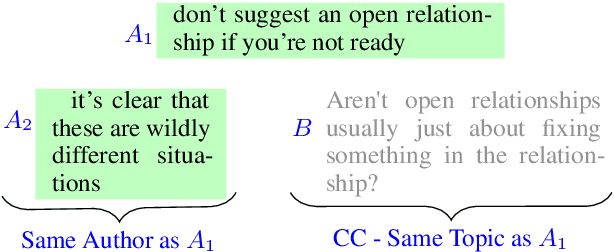
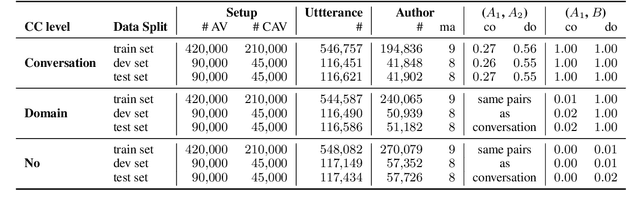
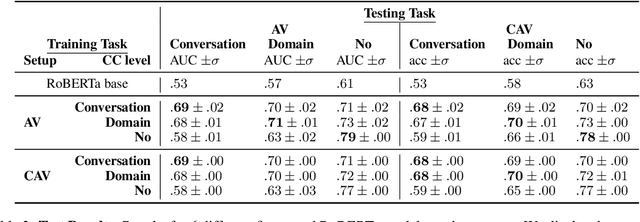

Linguistic style is an integral component of language. Recent advances in the development of style representations have increasingly used training objectives from authorship verification (AV): Do two texts have the same author? The assumption underlying the AV training task (same author approximates same writing style) enables self-supervised and, thus, extensive training. However, a good performance on the AV task does not ensure good "general-purpose" style representations. For example, as the same author might typically write about certain topics, representations trained on AV might also encode content information instead of style alone. We introduce a variation of the AV training task that controls for content using conversation or domain labels. We evaluate whether known style dimensions are represented and preferred over content information through an original variation to the recently proposed STEL framework. We find that representations trained by controlling for conversation are better than representations trained with domain or no content control at representing style independent from content.