 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProduct Market Demand Analysis Using NLP in Banglish Text with Sentiment Analysis and Named Entity Recognition
Paper and Code
Apr 04, 2022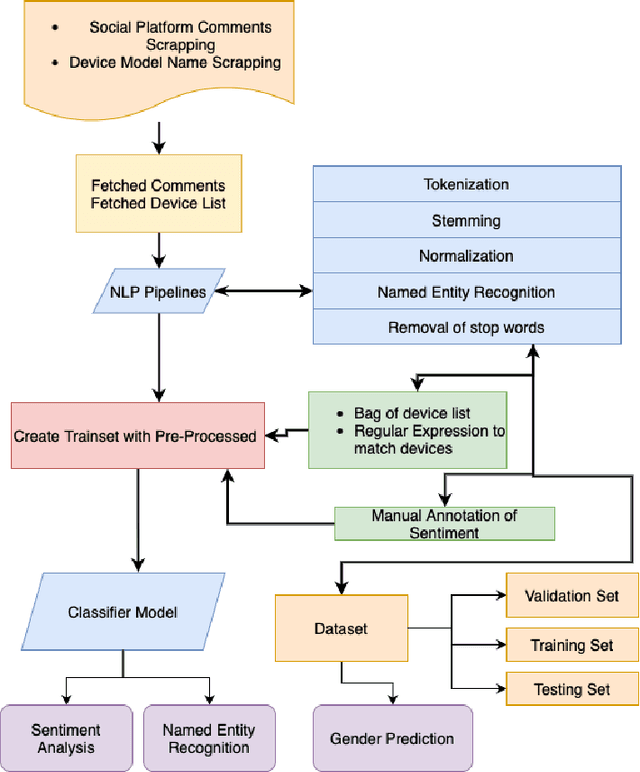

Product market demand analysis plays a significant role for originating business strategies due to its noticeable impact on the competitive business field. Furthermore, there are roughly 228 million native Bengali speakers, the majority of whom use Banglish text to interact with one another on social media. Consumers are buying and evaluating items on social media with Banglish text as social media emerges as an online marketplace for entrepreneurs. People use social media to find preferred smartphone brands and models by sharing their positive and bad experiences with them. For this reason, our goal is to gather Banglish text data and use sentiment analysis and named entity identification to assess Bangladeshi market demand for smartphones in order to determine the most popular smartphones by gender. We scraped product related data from social media with instant data scrapers and crawled data from Wikipedia and other sites for product information with python web scrapers. Using Python's Pandas and Seaborn libraries, the raw data is filtered using NLP methods. To train our datasets for named entity recognition, we utilized Spacey's custom NER model, Amazon Comprehend Custom NER. A tensorflow sequential model was deployed with parameter tweaking for sentiment analysis. Meanwhile, we used the Google Cloud Translation API to estimate the gender of the reviewers using the BanglaLinga library. In this article, we use natural language processing (NLP) approaches and several machine learning models to identify the most in-demand items and services in the Bangladeshi market. Our model has an accuracy of 87.99% in Spacy Custom Named Entity recognition, 95.51% in Amazon Comprehend Custom NER, and 87.02% in the Sequential model for demand analysis. After Spacy's study, we were able to manage 80% of mistakes related to misspelled words using a mix of Levenshtein distance and ratio algorithms.