 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape-Pose Disentanglement using SE(3)-equivariant Vector Neurons
Paper and Code
Apr 03, 2022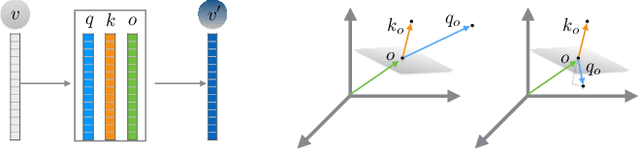
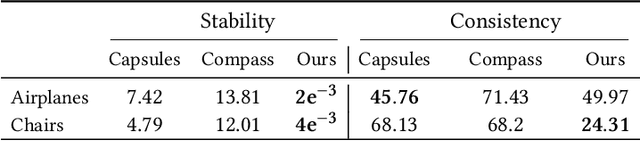
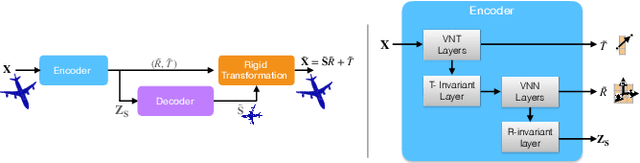
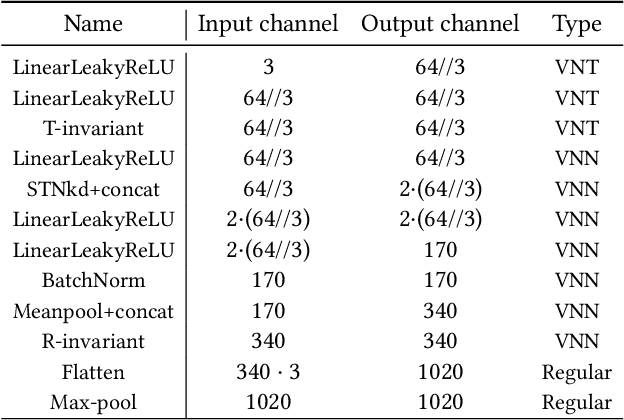
We introduce an unsupervised technique for encoding point clouds into a canonical shape representation, by disentangling shape and pose. Our encoder is stable and consistent, meaning that the shape encoding is purely pose-invariant, while the extracted rotation and translation are able to semantically align different input shapes of the same class to a common canonical pose. Specifically, we design an auto-encoder based on Vector Neuron Networks, a rotation-equivariant neural network, whose layers we extend to provide translation-equivariance in addition to rotation-equivariance only. The resulting encoder produces pose-invariant shape encoding by construction, enabling our approach to focus on learning a consistent canonical pose for a class of objects. Quantitative and qualitative experiments validate the superior stability and consistency of our approach.