 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-sequence Intermediate Conditioning for CTC-based ASR
Paper and Code
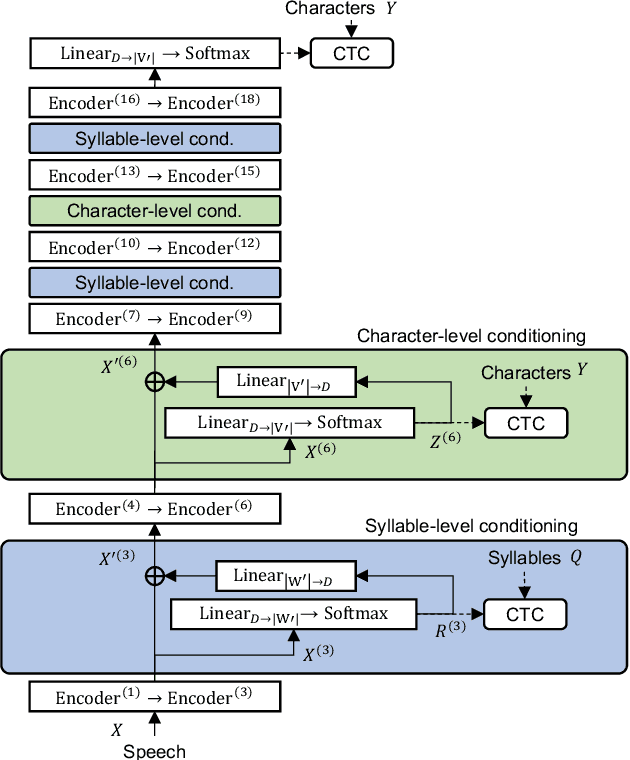
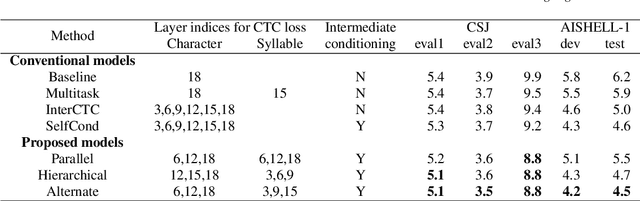


End-to-end automatic speech recognition (ASR) directly maps input speech to a character sequence without using pronunciation lexica. However, in languages with thousands of characters, such as Japanese and Mandarin, modeling all these characters is problematic due to data scarcity. To alleviate the problem, we propose a multi-task learning model with explicit interaction between characters and syllables by utilizing Self-conditioned connectionist temporal classification (CTC) technique. While the original Self-conditioned CTC estimates character-level intermediate predictions by applying auxiliary CTC losses to a set of intermediate layers, the proposed method additionally estimates syllable-level intermediate predictions in another set of intermediate layers. The character-level and syllable-level predictions are alternately used as conditioning features to deal with mutual dependency between characters and syllables. Experimental results on Japanese and Mandarin datasets show that the proposed multi-sequence intermediate conditioning outperformed the conventional multi-task-based and Self-conditioned CTC-based methods.