 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Word Error Rate a good evaluation metric for Speech Recognition in Indic Languages?
Paper and Code
Mar 30, 2022
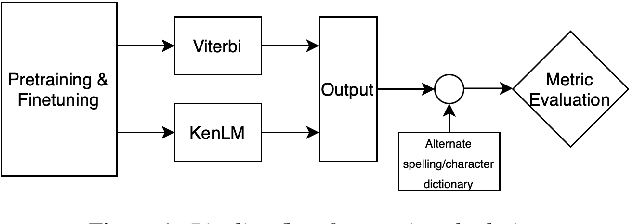

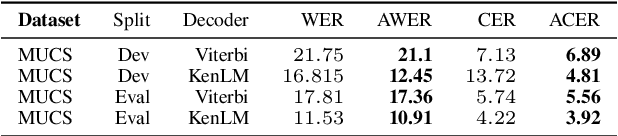
We propose a new method for the calculation of error rates in Automatic Speech Recognition (ASR). This new metric is for languages that contain half characters and where the same character can be written in different forms. We implement our methodology in Hindi which is one of the main languages from Indic context and we think this approach is scalable to other similar languages containing a large character set. We call our metrics Alternate Word Error Rate (AWER) and Alternate Character Error Rate (ACER). We train our ASR models using wav2vec 2.0\cite{baevski2020wav2vec} for Indic languages. Additionally we use language models to improve our model performance. Our results show a significant improvement in analyzing the error rates at word and character level and the interpretability of the ASR system is improved upto $3$\% in AWER and $7$\% in ACER for Hindi. Our experiments suggest that in languages which have complex pronunciation, there are multiple ways of writing words without changing their meaning. In such cases AWER and ACER will be more useful rather than WER and CER as metrics. Furthermore, we open source a new benchmarking dataset of 21 hours for Hindi with the new metric scripts.