Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Speech Recognition for Indic Languages using Language Model
Paper and Code
Mar 30, 2022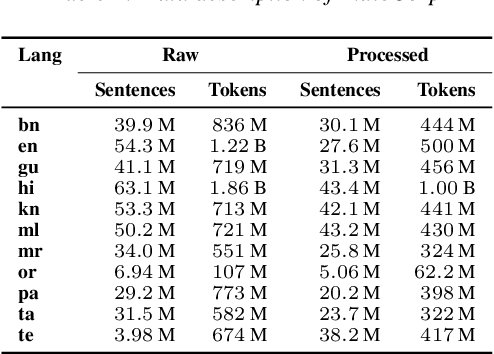
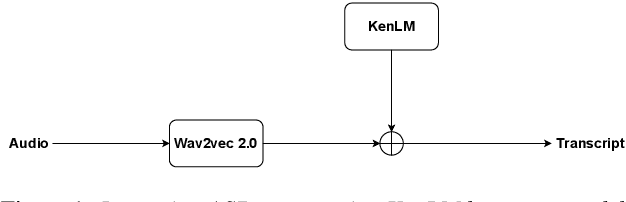
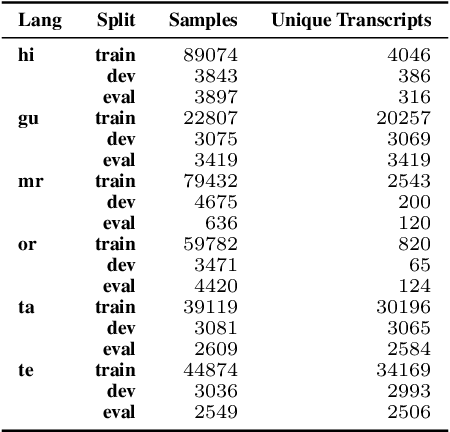
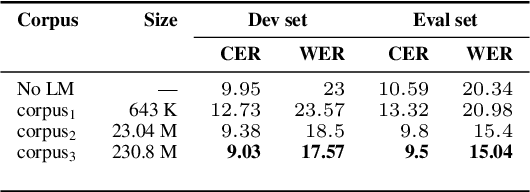
We study the effect of applying a language model (LM) on the output of Automatic Speech Recognition (ASR) systems for Indic languages. We fine-tune wav2vec $2.0$ models for $18$ Indic languages and adjust the results with language models trained on text derived from a variety of sources. Our findings demonstrate that the average Character Error Rate (CER) decreases by over $28$ \% and the average Word Error Rate (WER) decreases by about $36$ \% after decoding with LM. We show that a large LM may not provide a substantial improvement as compared to a diverse one. We also demonstrate that high quality transcriptions can be obtained on domain-specific data without retraining the ASR model and show results on biomedical domain.
* This paper was submitted to Interspeech 2022
View paper on