 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Switched and Code Mixed Speech Recognition for Indic languages
Paper and Code
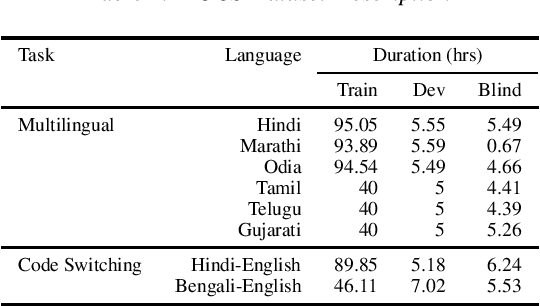

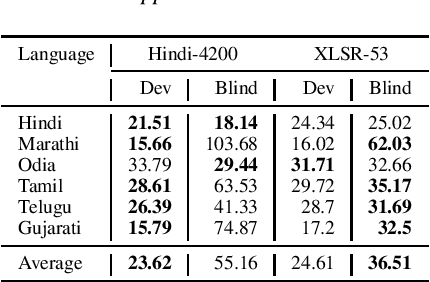
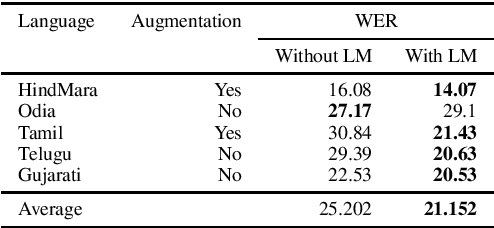
Training multilingual automatic speech recognition (ASR) systems is challenging because acoustic and lexical information is typically language specific. Training multilingual system for Indic languages is even more tougher due to lack of open source datasets and results on different approaches. We compare the performance of end to end multilingual speech recognition system to the performance of monolingual models conditioned on language identification (LID). The decoding information from a multilingual model is used for language identification and then combined with monolingual models to get an improvement of 50% WER across languages. We also propose a similar technique to solve the Code Switched problem and achieve a WER of 21.77 and 28.27 over Hindi-English and Bengali-English respectively. Our work talks on how transformer based ASR especially wav2vec 2.0 can be applied in developing multilingual ASR and code switched ASR for Indic languages.