 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Face Video Compression using Multiple Views
Paper and Code
Apr 13, 2022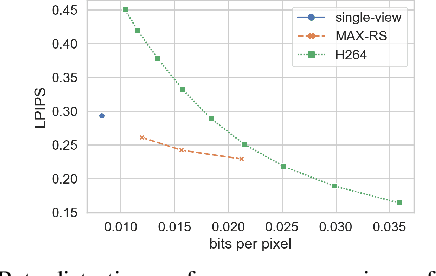
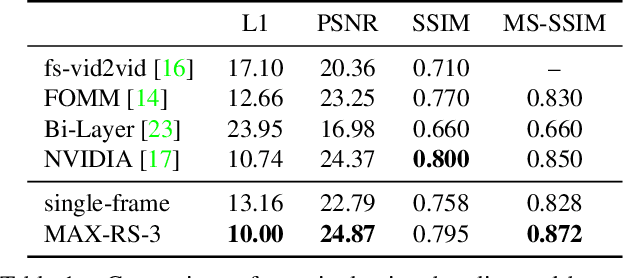

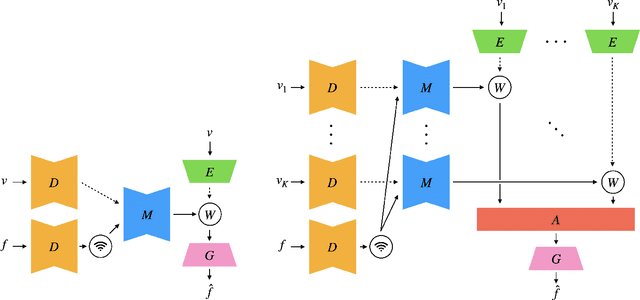
Recent advances in deep generative models led to the development of neural face video compression codecs that use an order of magnitude less bandwidth than engineered codecs. These neural codecs reconstruct the current frame by warping a source frame and using a generative model to compensate for imperfections in the warped source frame. Thereby, the warp is encoded and transmitted using a small number of keypoints rather than a dense flow field, which leads to massive savings compared to traditional codecs. However, by relying on a single source frame only, these methods lead to inaccurate reconstructions (e.g. one side of the head becomes unoccluded when turning the head and has to be synthesized). Here, we aim to tackle this issue by relying on multiple source frames (views of the face) and present encouraging results.