 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation Dataset for Legal Word Embedding: A Case Study On Chinese Codex
Paper and Code
Mar 29, 2022
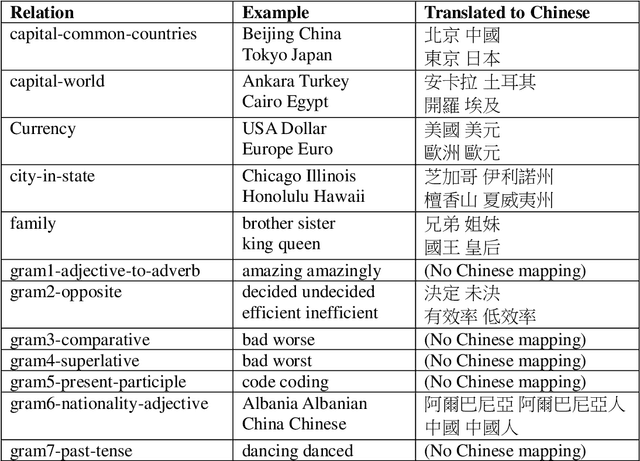
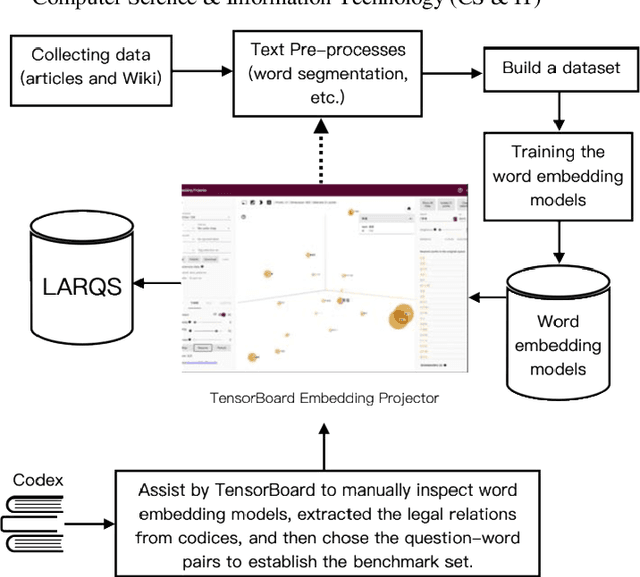
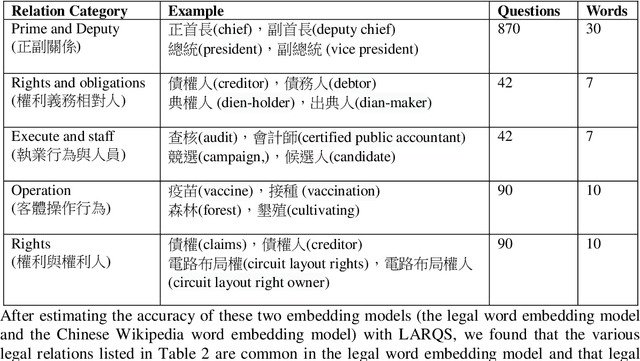
Word embedding is a modern distributed word representations approach widely used in many natural language processing tasks. Converting the vocabulary in a legal document into a word embedding model facilitates subjecting legal documents to machine learning, deep learning, and other algorithms and subsequently performing the downstream tasks of natural language processing vis-\`a-vis, for instance, document classification, contract review, and machine translation. The most common and practical approach of accuracy evaluation with the word embedding model uses a benchmark set with linguistic rules or the relationship between words to perform analogy reasoning via algebraic calculation. This paper proposes establishing a 1,134 Legal Analogical Reasoning Questions Set (LARQS) from the 2,388 Chinese Codex corpus using five kinds of legal relations, which are then used to evaluate the accuracy of the Chinese word embedding model. Moreover, we discovered that legal relations might be ubiquitous in the word embedding model.