 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Token-Level and Passage-Level Dense Retrieval Models for Math Information Retrieval
Paper and Code
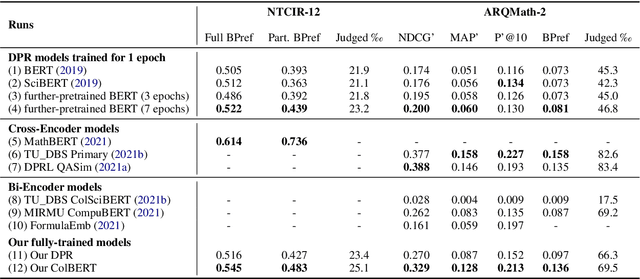
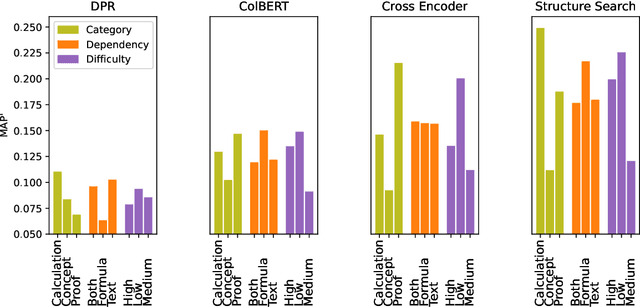
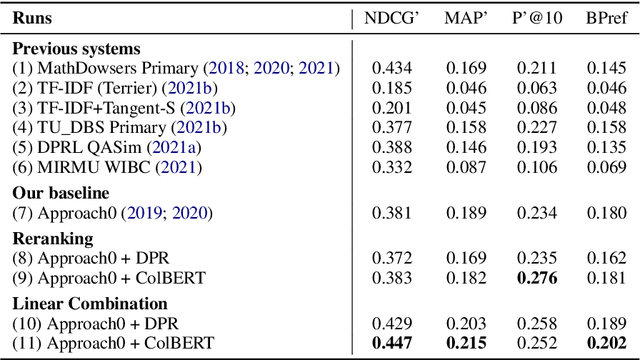
With the recent success of dense retrieval methods based on bi-encoders, a number of studies have applied this approach to various interesting downstream retrieval tasks with good efficiency and in-domain effectiveness. Recently, we have also seen the presence of dense retrieval models in Math Information Retrieval (MIR) tasks, but the most effective systems remain "classic" retrieval methods that consider rich structure features. In this work, we try to combine the best of both worlds: a well-defined structure search method for effective formula search and bi-encoder dense retrieval models to capture contextual similarities in mathematical documents. Specifically, we have evaluated two representative bi-encoder models (ColBERT and DPR) for token-level and passage-level dense retrieval on recent MIR tasks. To our best knowledge, this is the first time a DPR model has been evaluated in the MIR domain. Our result shows that bi-encoder models are complementary to existing structure search methods, and we are able to advance the state of the art on a recent MIR dataset. We have made our model checkpoints and source code publicly available for the reproduction of our results.