 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Imitation Learning from Demonstrations
Paper and Code
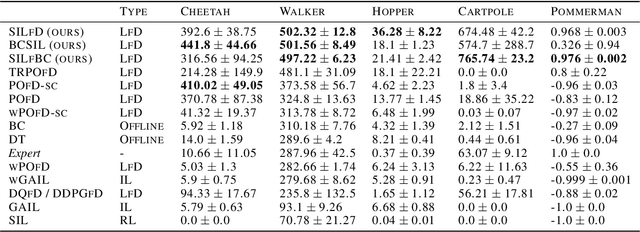
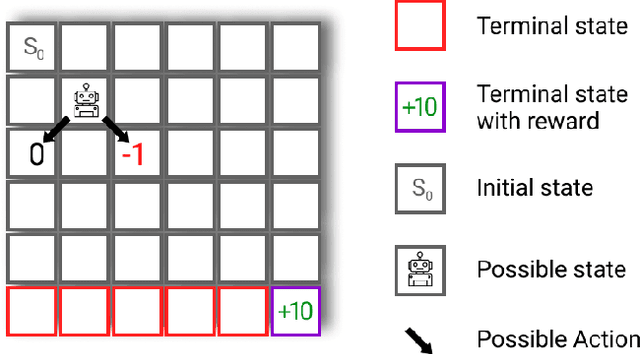
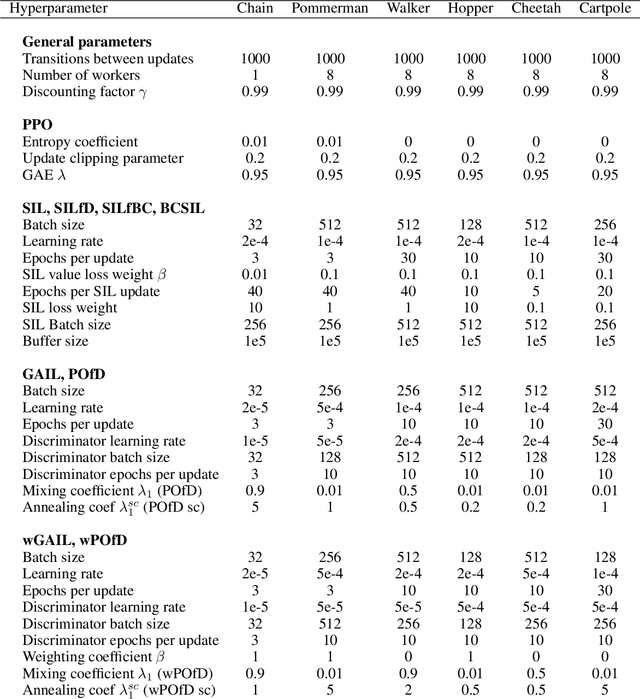
Despite the numerous breakthroughs achieved with Reinforcement Learning (RL), solving environments with sparse rewards remains a challenging task that requires sophisticated exploration. Learning from Demonstrations (LfD) remedies this issue by guiding the agent's exploration towards states experienced by an expert. Naturally, the benefits of this approach hinge on the quality of demonstrations, which are rarely optimal in realistic scenarios. Modern LfD algorithms require meticulous tuning of hyperparameters that control the influence of demonstrations and, as we show in the paper, struggle with learning from suboptimal demonstrations. To address these issues, we extend Self-Imitation Learning (SIL), a recent RL algorithm that exploits the agent's past good experience, to the LfD setup by initializing its replay buffer with demonstrations. We denote our algorithm as SIL from Demonstrations (SILfD). We empirically show that SILfD can learn from demonstrations that are noisy or far from optimal and can automatically adjust the influence of demonstrations throughout the training without additional hyperparameters or handcrafted schedules. We also find SILfD superior to the existing state-of-the-art LfD algorithms in sparse environments, especially when demonstrations are highly suboptimal.