 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection in Big Data
Paper and Code
Mar 03, 2022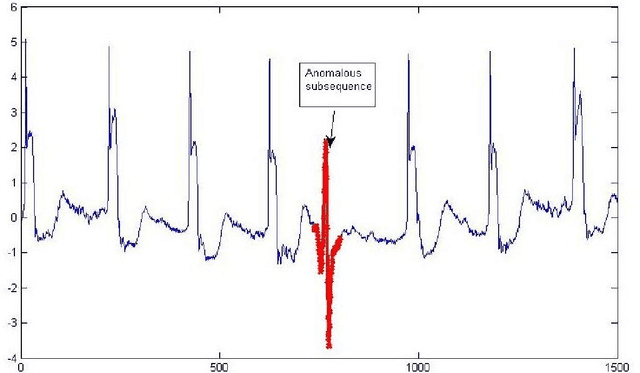

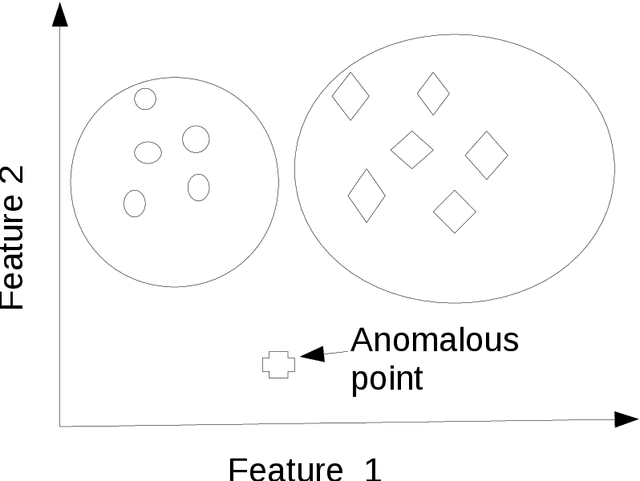
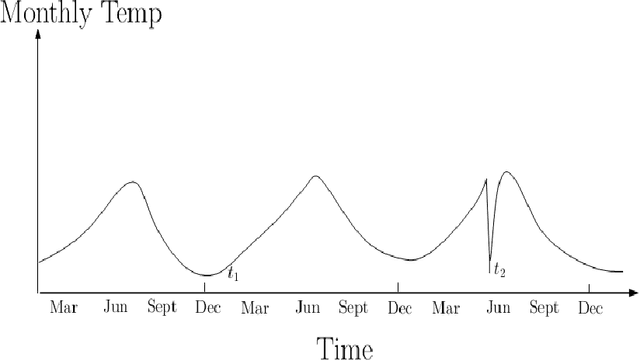
Anomaly is defined as a state of the system that do not conform to the normal behavior. For example, the emission of neutrons in a nuclear reactor channel above the specified threshold is an anomaly. Big data refers to the data set that is \emph{high volume, streaming, heterogeneous, distributed} and often \emph{sparse}. Big data is not uncommon these days. For example, as per Internet live stats, the number of tweets posted per day has gone above 500 millions. Due to data explosion in data laden domains, traditional anomaly detection techniques developed for small data sets scale poorly on large-scale data sets. Therefore, we take an alternative approach to tackle anomaly detection in big data. Essentially, there are two ways to scale anomaly detection in big data. The first is based on the \emph{online} learning and the second is based on the \emph{distributed} learning. Our aim in the thesis is to tackle big data problems while detecting anomaly efficiently. To that end, we first take \emph{streaming} issue of the big data and propose Passive-Aggressive GMEAN (PAGMEAN) algorithms. Although, online learning algorithm can scale well over large number of data points and dimensions, they can not process data when it is distributed at multiple locations; which is quite common these days. Therefore, we propose anomaly detection algorithm which is inherently distributed using ADMM. Finally, we present a case study on anomaly detection in nuclear power plant data.