 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible variable selection in the presence of missing data
Paper and Code
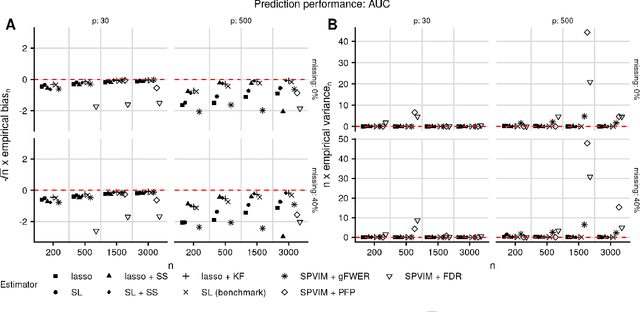
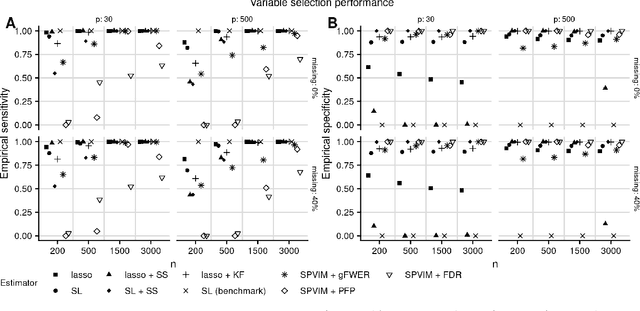
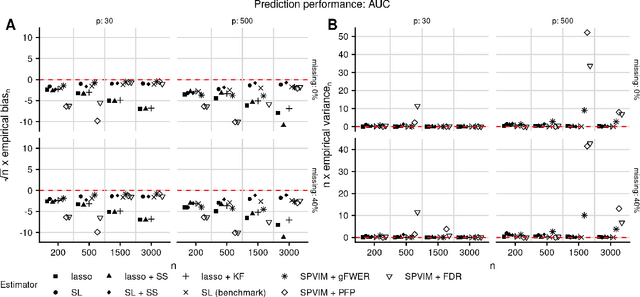
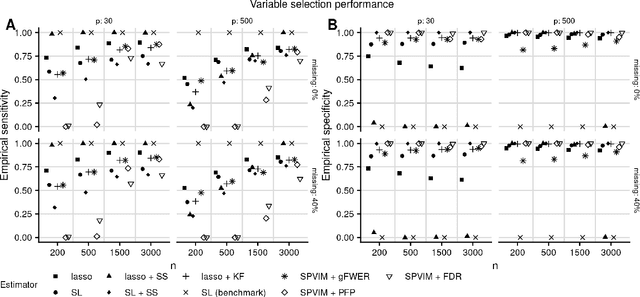
In many applications, it is of interest to identify a parsimonious set of features, or panel, from multiple candidates that achieves a desired level of performance in predicting a response. This task is often complicated in practice by missing data arising from the sampling design or other random mechanisms. Most recent work on variable selection in missing data contexts relies in some part on a finite-dimensional statistical model (e.g., a generalized or penalized linear model). In cases where this model is misspecified, the selected variables may not all be truly scientifically relevant and can result in panels with suboptimal classification performance. To address this limitation, we propose several nonparametric variable selection algorithms combined with multiple imputation to develop flexible panels in the presence of missing-at-random data. We outline strategies based on the proposed algorithms that achieve control of commonly used error rates. Through simulations, we show that our proposals have good operating characteristics and result in panels with higher classification performance compared to several existing penalized regression approaches. Finally, we use the proposed methods to develop biomarker panels for separating pancreatic cysts with differing malignancy potential in a setting where complicated missingness in the biomarkers arose due to limited specimen volumes.