 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Meta-Initialization with Task Augmentation for Kindergarten-aged Speech Recognition
Paper and Code
Feb 24, 2022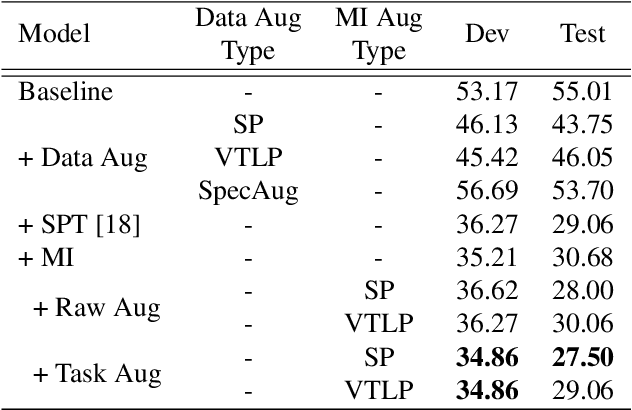
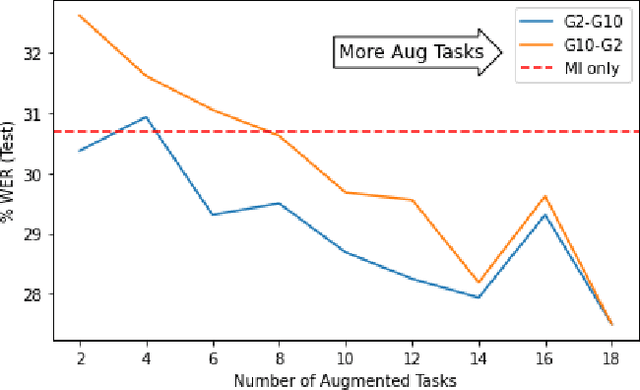
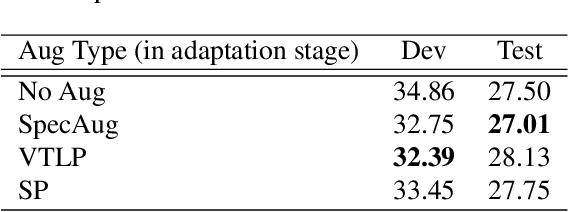
Children's automatic speech recognition (ASR) is always difficult due to, in part, the data scarcity problem, especially for kindergarten-aged kids. When data are scarce, the model might overfit to the training data, and hence good starting points for training are essential. Recently, meta-learning was proposed to learn model initialization (MI) for ASR tasks of different languages. This method leads to good performance when the model is adapted to an unseen language. However, MI is vulnerable to overfitting on training tasks (learner overfitting). It is also unknown whether MI generalizes to other low-resource tasks. In this paper, we validate the effectiveness of MI in children's ASR and attempt to alleviate the problem of learner overfitting. To achieve model-agnostic meta-learning (MAML), we regard children's speech at each age as a different task. In terms of learner overfitting, we propose a task-level augmentation method by simulating new ages using frequency warping techniques. Detailed experiments are conducted to show the impact of task augmentation on each age for kindergarten-aged speech. As a result, our approach achieves a relative word error rate (WER) improvement of 51% over the baseline system with no augmentation or initialization.