 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Top-k Selection via Canonical Lipschitz Mechanism
Paper and Code
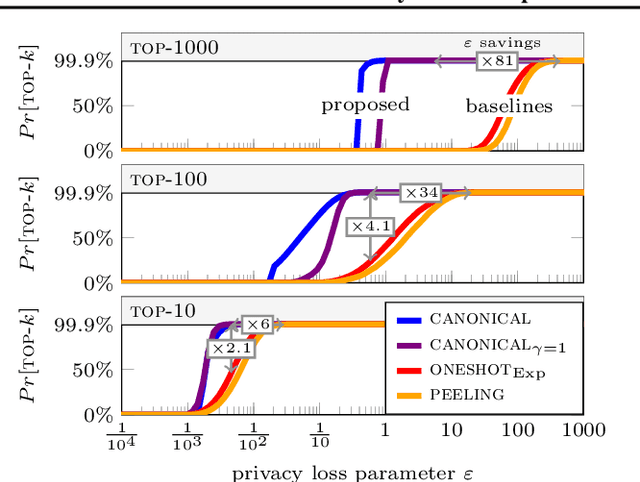

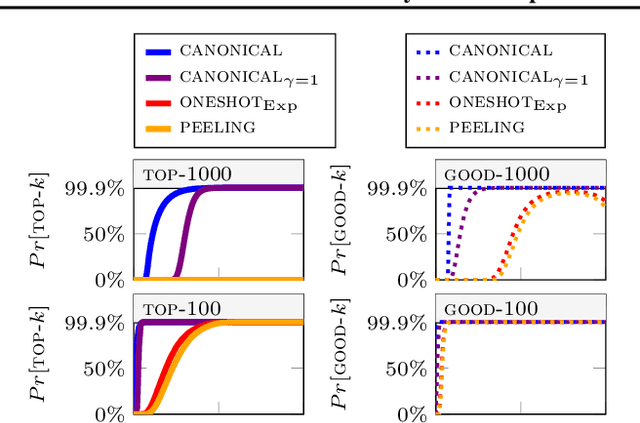
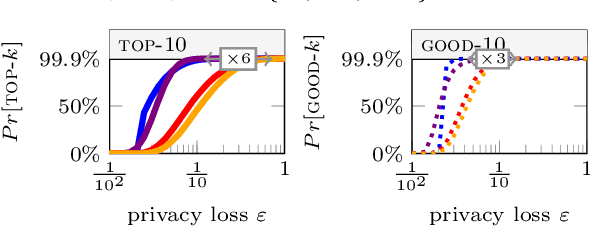
Selecting the top-$k$ highest scoring items under differential privacy (DP) is a fundamental task with many applications. This work presents three new results. First, the exponential mechanism, permute-and-flip and report-noisy-max, as well as their oneshot variants, are unified into the Lipschitz mechanism, an additive noise mechanism with a single DP-proof via a mandated Lipschitz property for the noise distribution. Second, this new generalized mechanism is paired with a canonical loss function to obtain the canonical Lipschitz mechanism, which can directly select k-subsets out of $d$ items in $O(dk+d \log d)$ time. The canonical loss function assesses subsets by how many users must change for the subset to become top-$k$. Third, this composition-free approach to subset selection improves utility guarantees by an $\Omega(\log k)$ factor compared to one-by-one selection via sequential composition, and our experiments on synthetic and real-world data indicate substantial utility improvements.