 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fairness Field Guide: Perspectives from Social and Formal Sciences
Paper and Code
Jan 13, 2022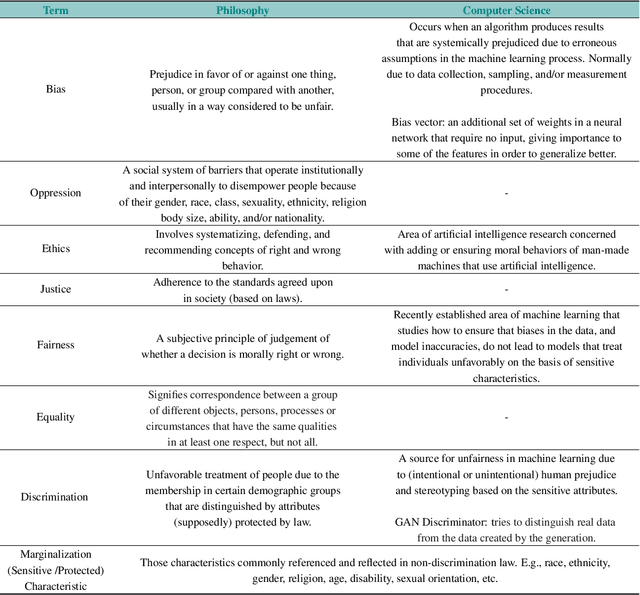

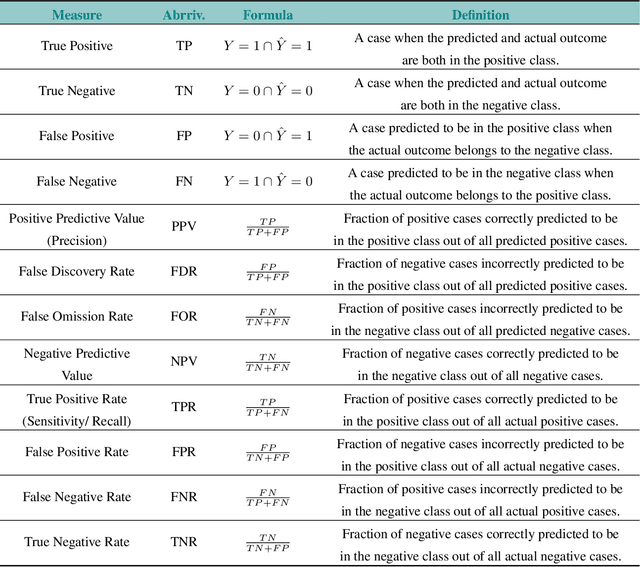
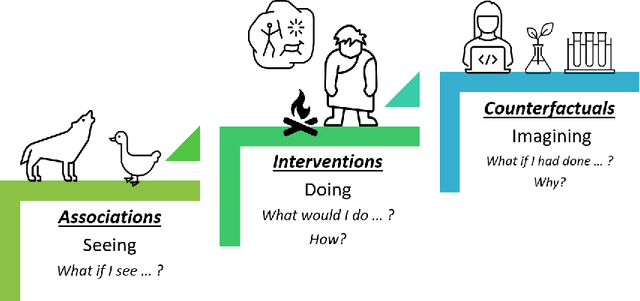
Over the past several years, a slew of different methods to measure the fairness of a machine learning model have been proposed. However, despite the growing number of publications and implementations, there is still a critical lack of literature that explains the interplay of fair machine learning with the social sciences of philosophy, sociology, and law. We hope to remedy this issue by accumulating and expounding upon the thoughts and discussions of fair machine learning produced by both social and formal (specifically machine learning and statistics) sciences in this field guide. Specifically, in addition to giving the mathematical and algorithmic backgrounds of several popular statistical and causal-based fair machine learning methods, we explain the underlying philosophical and legal thoughts that support them. Further, we explore several criticisms of the current approaches to fair machine learning from sociological and philosophical viewpoints. It is our hope that this field guide will help fair machine learning practitioners better understand how their algorithms align with important humanistic values (such as fairness) and how we can, as a field, design methods and metrics to better serve oppressed and marginalized populaces.