 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxicity Detection for Indic Multilingual Social Media Content
Paper and Code
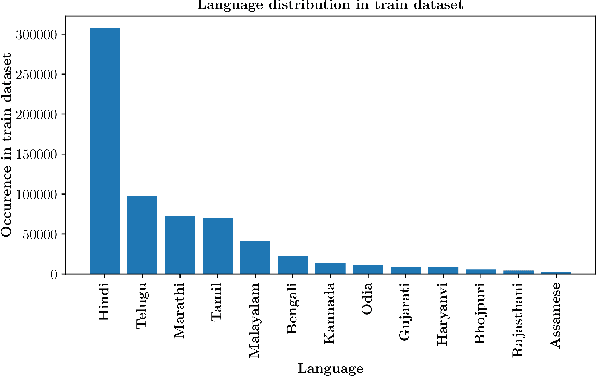
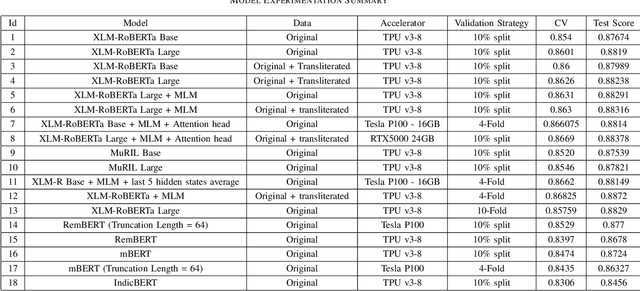
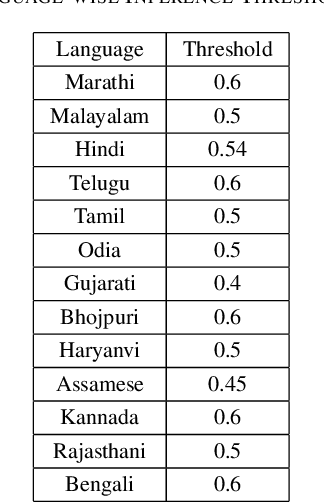
Toxic content is one of the most critical issues for social media platforms today. India alone had 518 million social media users in 2020. In order to provide a good experience to content creators and their audience, it is crucial to flag toxic comments and the users who post that. But the big challenge is identifying toxicity in low resource Indic languages because of the presence of multiple representations of the same text. Moreover, the posts/comments on social media do not adhere to a particular format, grammar or sentence structure; this makes the task of abuse detection even more challenging for multilingual social media platforms. This paper describes the system proposed by team 'Moj Masti' using the data provided by ShareChat/Moj in \emph{IIIT-D Multilingual Abusive Comment Identification} challenge. We focus on how we can leverage multilingual transformer based pre-trained and fine-tuned models to approach code-mixed/code-switched classification tasks. Our best performing system was an ensemble of XLM-RoBERTa and MuRIL which achieved a Mean F-1 score of 0.9 on the test data/leaderboard. We also observed an increase in the performance by adding transliterated data. Furthermore, using weak metadata, ensembling and some post-processing techniques boosted the performance of our system, thereby placing us 1st on the leaderboard.