 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Online Data-Driven Emergency-Response Method for Autonomous Agents in Unforeseen Situations
Paper and Code
Dec 17, 2021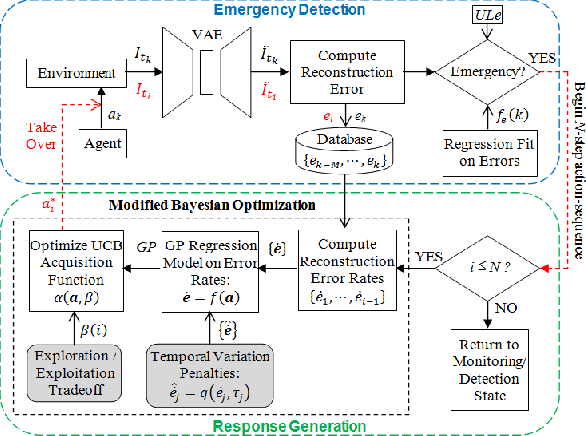
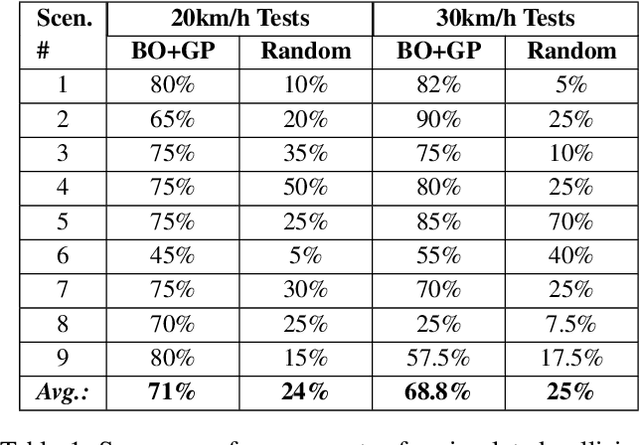

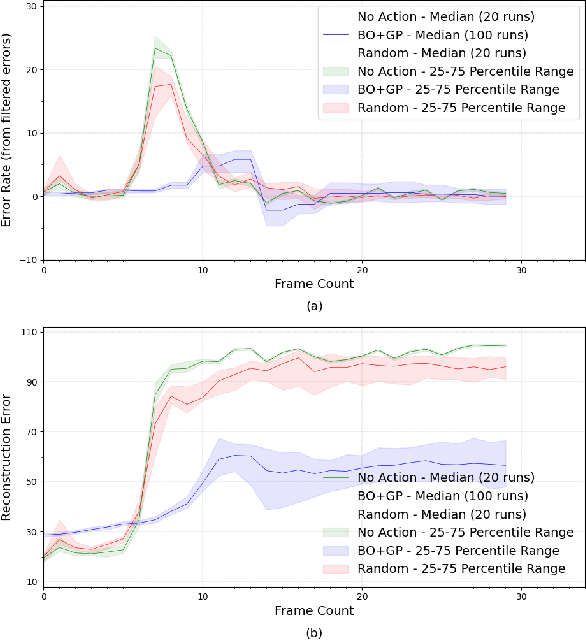
Reinforcement learning agents perform well when presented with inputs within the distribution of those encountered during training. However, they are unable to respond effectively when faced with novel, out-of-distribution events, until they have undergone additional training. This paper presents an online, data-driven, emergency-response method that aims to provide autonomous agents the ability to react to unexpected situations that are very different from those it has been trained or designed to address. In such situations, learned policies cannot be expected to perform appropriately since the observations obtained in these novel situations would fall outside the distribution of inputs that the agent has been optimized to handle. The proposed approach devises a customized response to the unforeseen situation sequentially, by selecting actions that minimize the rate of increase of the reconstruction error from a variational auto-encoder. This optimization is achieved online in a data-efficient manner (on the order of 30 data-points) using a modified Bayesian optimization procedure. We demonstrate the potential of this approach in a simulated 3D car driving scenario, in which the agent devises a response in under 2 seconds to avoid collisions with objects it has not seen during training.