 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Need One Model for Open-domain Question Answering
Paper and Code
Dec 14, 2021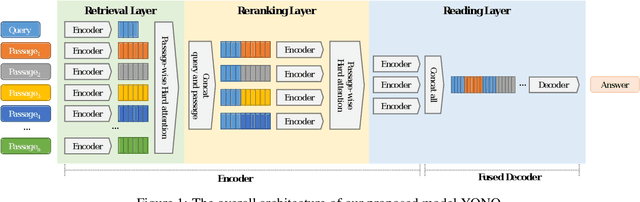
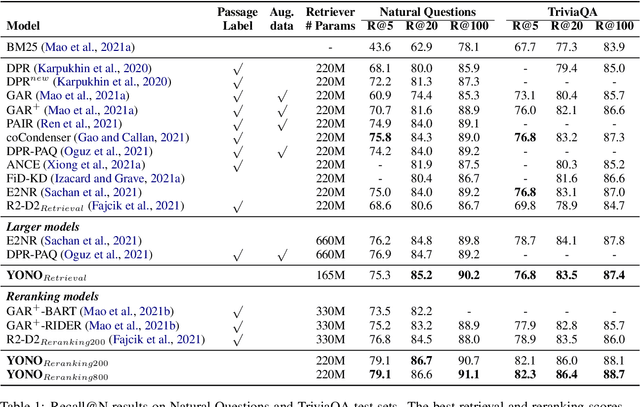
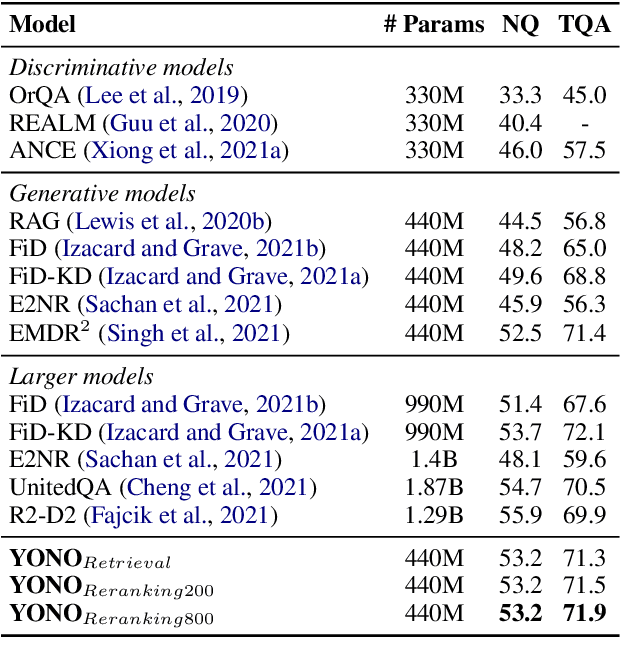
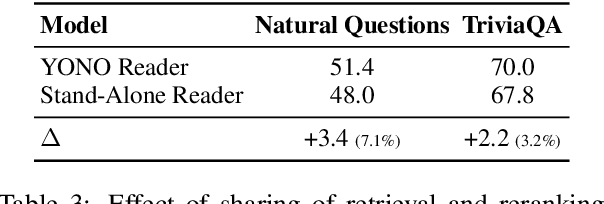
Recent works for Open-domain Question Answering refer to an external knowledge base using a retriever model, optionally rerank the passages with a separate reranker model and generate an answer using an another reader model. Despite performing related tasks, the models have separate parameters and are weakly-coupled during training. In this work, we propose casting the retriever and the reranker as hard-attention mechanisms applied sequentially within the transformer architecture and feeding the resulting computed representations to the reader. In this singular model architecture the hidden representations are progressively refined from the retriever to the reranker to the reader, which is more efficient use of model capacity and also leads to better gradient flow when we train it in an end-to-end manner. We also propose a pre-training methodology to effectively train this architecture. We evaluate our model on Natural Questions and TriviaQA open datasets and for a fixed parameter budget, our model outperforms the previous state-of-the-art model by 1.0 and 0.7 exact match scores.