 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEO-BLEU: Similarity Measure for Geospatial Sequences
Paper and Code
Dec 14, 2021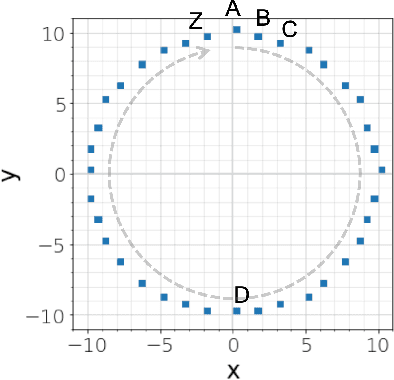

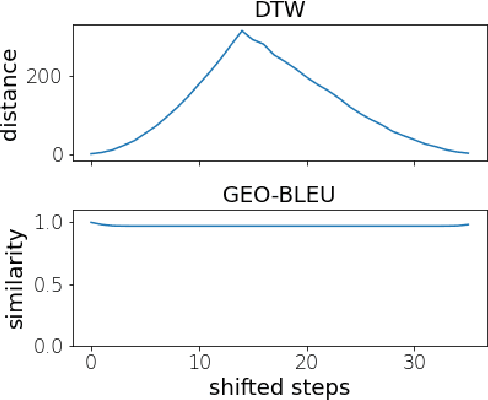
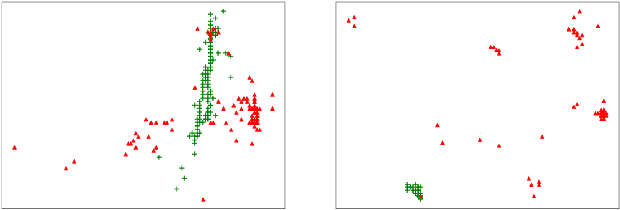
In recent geospatial research, the importance of modeling large-scale human mobility data via self-supervised learning is rising, in parallel with progress in natural language processing driven by self-supervised approaches using large-scale corpora. Whereas there are already plenty of feasible approaches applicable to geospatial sequence modeling itself, there seems to be room to improve with regard to evaluation, specifically about how to measure the similarity between generated and reference sequences. In this work, we propose a novel similarity measure, GEO-BLEU, which can be especially useful in the context of geospatial sequence modeling and generation. As the name suggests, this work is based on BLEU, one of the most popular measures used in machine translation research, while introducing spatial proximity to the idea of n-gram. We compare this measure with an established baseline, dynamic time warping, applying it to actual generated geospatial sequences. Using crowdsourced annotated data on the similarity between geospatial sequences collected from over 12,000 cases, we quantitatively and qualitatively show the proposed method's superiority.