 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidimensional Leaderboards: Generate and Evaluate Language Hand in Hand
Paper and Code
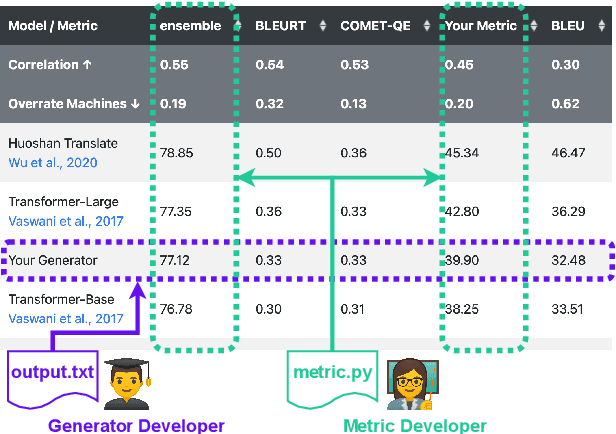
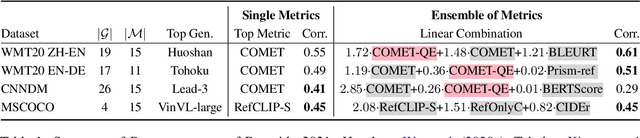
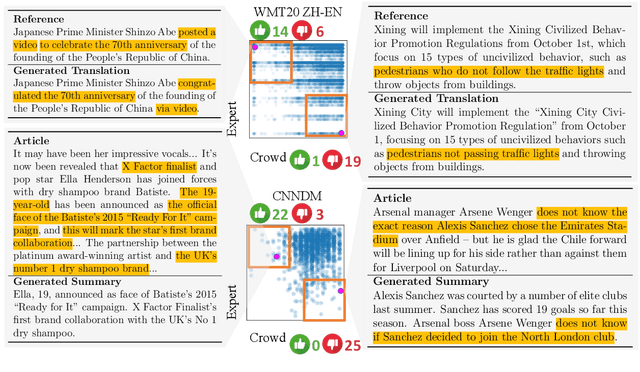

Natural language processing researchers have identified limitations of evaluation methodology for generation tasks, with new questions raised about the validity of automatic metrics and of crowdworker judgments. Meanwhile, efforts to improve generation models tend to focus on simple n-gram overlap metrics (e.g., BLEU, ROUGE). We argue that new advances on models and metrics should each more directly benefit and inform the other. We therefore propose a generalization of leaderboards, bidimensional leaderboards (Billboards), that simultaneously tracks progress in language generation tasks and metrics for their evaluation. Unlike conventional unidimensional leaderboards that sort submitted systems by predetermined metrics, a Billboard accepts both generators and evaluation metrics as competing entries. A Billboard automatically creates an ensemble metric that selects and linearly combines a few metrics based on a global analysis across generators. Further, metrics are ranked based on their correlations with human judgments. We release four Billboards for machine translation, summarization, and image captioning. We demonstrate that a linear ensemble of a few diverse metrics sometimes substantially outperforms existing metrics in isolation. Our mixed-effects model analysis shows that most automatic metrics, especially the reference-based ones, overrate machine over human generation, demonstrating the importance of updating metrics as generation models become stronger (and perhaps more similar to humans) in the future.