 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKazNERD: Kazakh Named Entity Recognition Dataset
Paper and Code
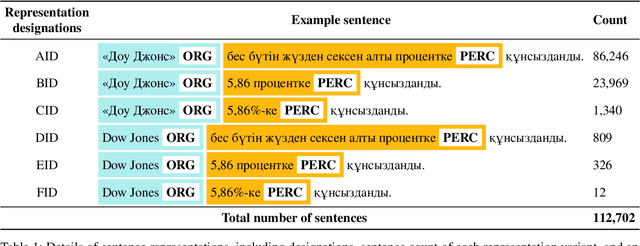


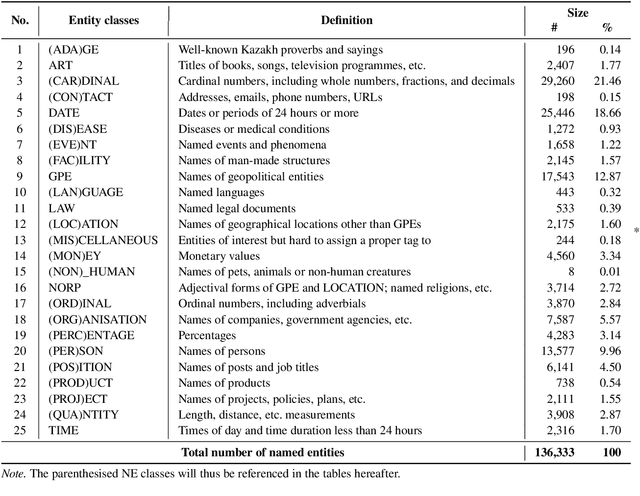
We present the development of a dataset for Kazakh named entity recognition. The dataset was built as there is a clear need for publicly available annotated corpora in Kazakh, as well as annotation guidelines containing straightforward--but rigorous--rules and examples. The dataset annotation, based on the IOB2 scheme, was carried out on television news text by two native Kazakh speakers under the supervision of the first author. The resulting dataset contains 112,702 sentences and 136,333 annotations for 25 entity classes. State-of-the-art machine learning models to automatise Kazakh named entity recognition were also built, with the best-performing model achieving an exact match F1-score of 97.22% on the test set. The annotated dataset, guidelines, and codes used to train the models are freely available for download under the CC BY 4.0 licence from https://github.com/IS2AI/KazNERD.