 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlant 'n' Seek: Can You Find the Winning Ticket?
Paper and Code
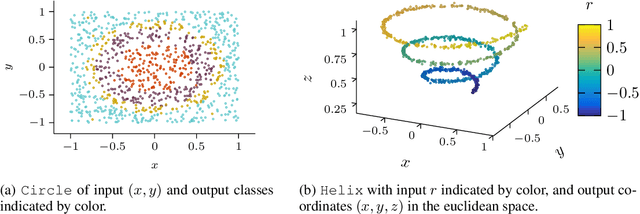
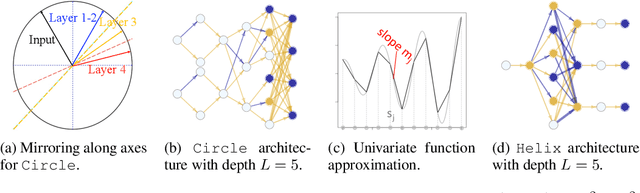
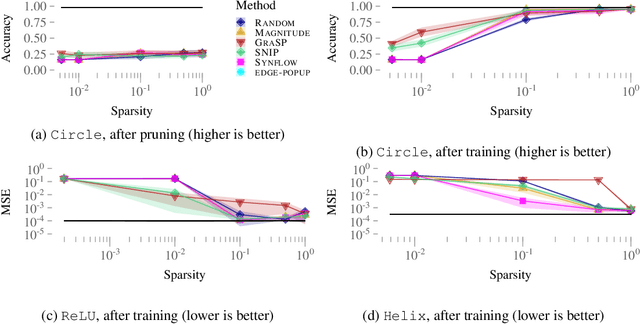
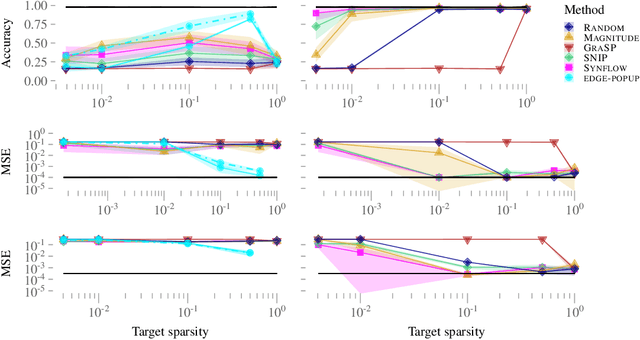
The lottery ticket hypothesis has sparked the rapid development of pruning algorithms that perform structure learning by identifying a sparse subnetwork of a large randomly initialized neural network. The existence of such 'winning tickets' has been proven theoretically but at suboptimal sparsity levels. Contemporary pruning algorithms have furthermore been struggling to identify sparse lottery tickets for complex learning tasks. Is this suboptimal sparsity merely an artifact of existence proofs and algorithms or a general limitation of the pruning approach? And, if very sparse tickets exist, are current algorithms able to find them or are further improvements needed to achieve effective network compression? To answer these questions systematically, we derive a framework to plant and hide target architectures within large randomly initialized neural networks. For three common challenges in machine learning, we hand-craft extremely sparse network topologies, plant them in large neural networks, and evaluate state-of-the-art lottery ticket pruning methods. We find that current limitations of pruning algorithms to identify extremely sparse tickets are likely of algorithmic rather than fundamental nature and anticipate that our planting framework will facilitate future developments of efficient pruning algorithms, as we have addressed the issue of missing baselines in the field raised by Frankle et al.