 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMyope Models -- Are face presentation attack detection models short-sighted?
Paper and Code
Nov 22, 2021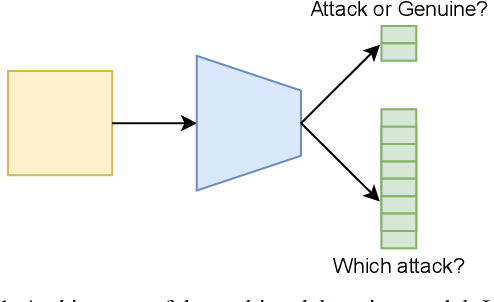

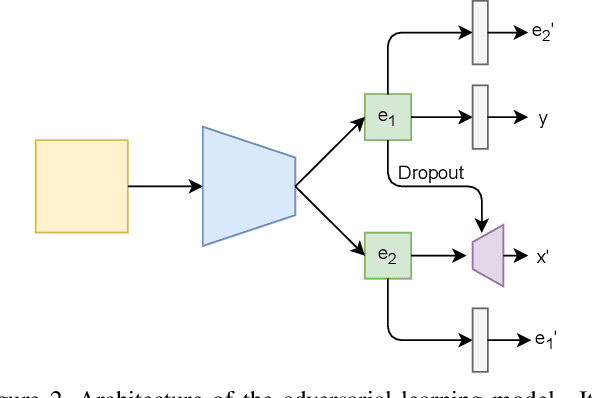
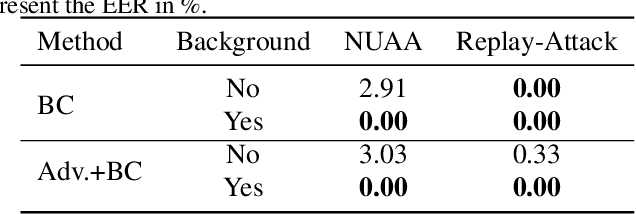
Presentation attacks are recurrent threats to biometric systems, where impostors attempt to bypass these systems. Humans often use background information as contextual cues for their visual system. Yet, regarding face-based systems, the background is often discarded, since face presentation attack detection (PAD) models are mostly trained with face crops. This work presents a comparative study of face PAD models (including multi-task learning, adversarial training and dynamic frame selection) in two settings: with and without crops. The results show that the performance is consistently better when the background is present in the images. The proposed multi-task methodology beats the state-of-the-art results on the ROSE-Youtu dataset by a large margin with an equal error rate of 0.2%. Furthermore, we analyze the models' predictions with Grad-CAM++ with the aim to investigate to what extent the models focus on background elements that are known to be useful for human inspection. From this analysis we can conclude that the background cues are not relevant across all the attacks. Thus, showing the capability of the model to leverage the background information only when necessary.