 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Dynamic Topic Model for Recognition of Lead-lag Relationship in Two Text Corpora
Paper and Code
Nov 21, 2021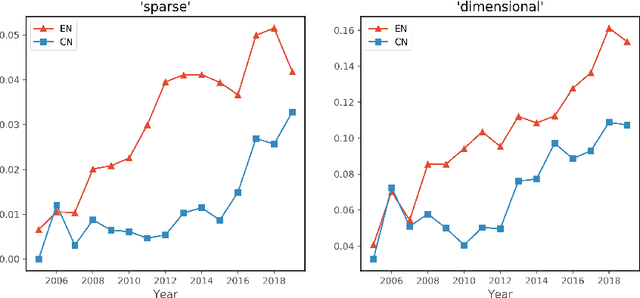
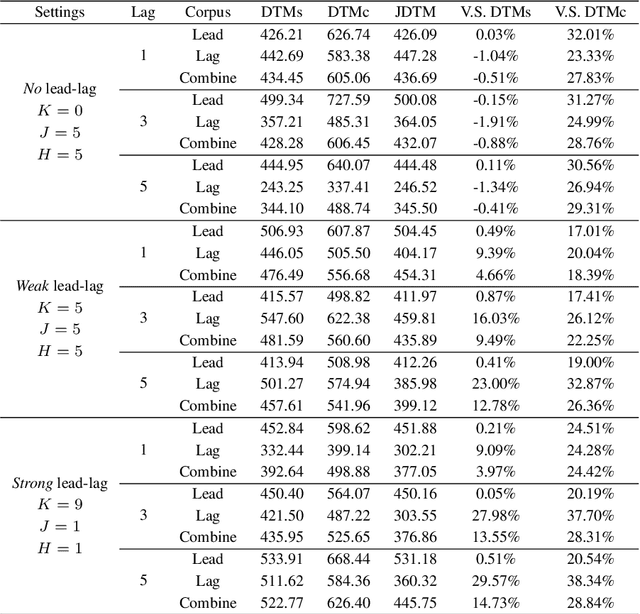
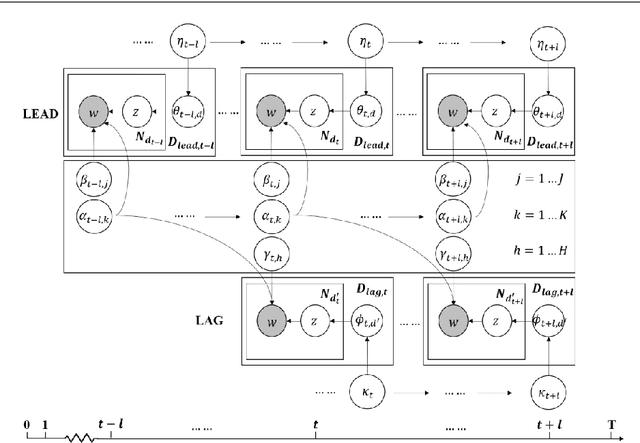
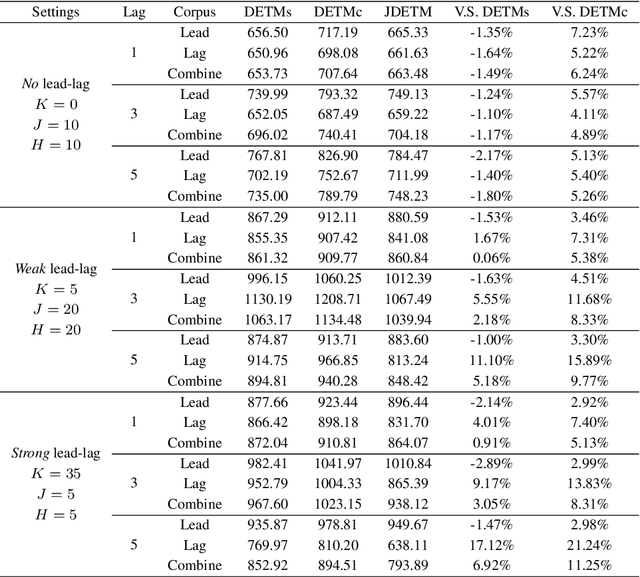
Topic evolution modeling has received significant attentions in recent decades. Although various topic evolution models have been proposed, most studies focus on the single document corpus. However in practice, we can easily access data from multiple sources and also observe relationships between them. Then it is of great interest to recognize the relationship between multiple text corpora and further utilize this relationship to improve topic modeling. In this work, we focus on a special type of relationship between two text corpora, which we define as the "lead-lag relationship". This relationship characterizes the phenomenon that one text corpus would influence the topics to be discussed in the other text corpus in the future. To discover the lead-lag relationship, we propose a jointly dynamic topic model and also develop an embedding extension to address the modeling problem of large-scale text corpus. With the recognized lead-lag relationship, the similarities of the two text corpora can be figured out and the quality of topic learning in both corpora can be improved. We numerically investigate the performance of the jointly dynamic topic modeling approach using synthetic data. Finally, we apply the proposed model on two text corpora consisting of statistical papers and the graduation theses. Results show the proposed model can well recognize the lead-lag relationship between the two corpora, and the specific and shared topic patterns in the two corpora are also discovered.