 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Quality Streaming Speech Synthesis with Low, Sentence-Length-Independent Latency
Paper and Code
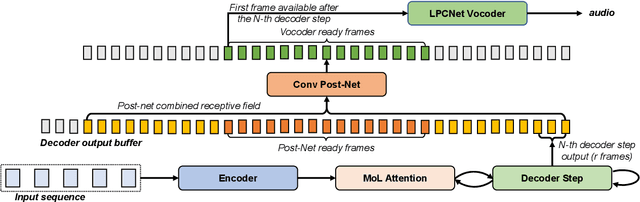
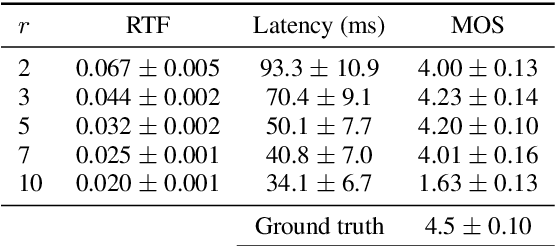
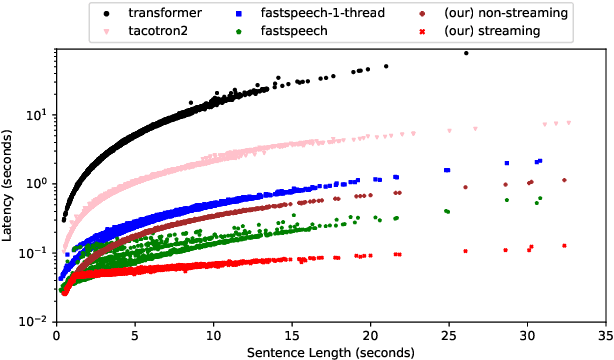
This paper presents an end-to-end text-to-speech system with low latency on a CPU, suitable for real-time applications. The system is composed of an autoregressive attention-based sequence-to-sequence acoustic model and the LPCNet vocoder for waveform generation. An acoustic model architecture that adopts modules from both the Tacotron 1 and 2 models is proposed, while stability is ensured by using a recently proposed purely location-based attention mechanism, suitable for arbitrary sentence length generation. During inference, the decoder is unrolled and acoustic feature generation is performed in a streaming manner, allowing for a nearly constant latency which is independent from the sentence length. Experimental results show that the acoustic model can produce feature sequences with minimal latency about 31 times faster than real-time on a computer CPU and 6.5 times on a mobile CPU, enabling it to meet the conditions required for real-time applications on both devices. The full end-to-end system can generate almost natural quality speech, which is verified by listening tests.