 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman irrationality: both bad and good for reward inference
Paper and Code
Nov 12, 2021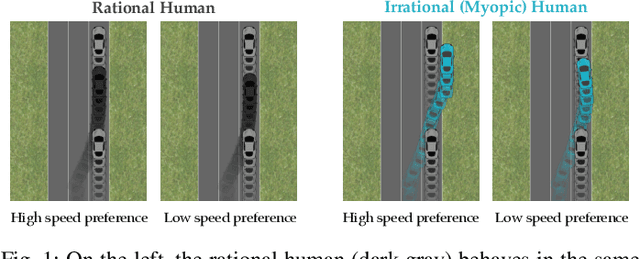

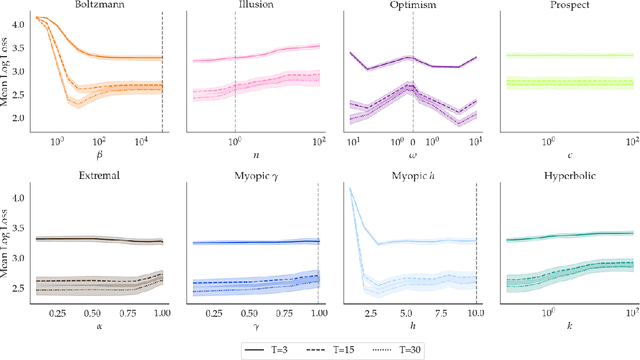
Assuming humans are (approximately) rational enables robots to infer reward functions by observing human behavior. But people exhibit a wide array of irrationalities, and our goal with this work is to better understand the effect they can have on reward inference. The challenge with studying this effect is that there are many types of irrationality, with varying degrees of mathematical formalization. We thus operationalize irrationality in the language of MDPs, by altering the Bellman optimality equation, and use this framework to study how these alterations would affect inference. We find that wrongly modeling a systematically irrational human as noisy-rational performs a lot worse than correctly capturing these biases -- so much so that it can be better to skip inference altogether and stick to the prior! More importantly, we show that an irrational human, when correctly modelled, can communicate more information about the reward than a perfectly rational human can. That is, if a robot has the correct model of a human's irrationality, it can make an even stronger inference than it ever could if the human were rational. Irrationality fundamentally helps rather than hinder reward inference, but it needs to be correctly accounted for.