 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Minimax Learning Approach to Off-Policy Evaluation in Partially Observable Markov Decision Processes
Paper and Code
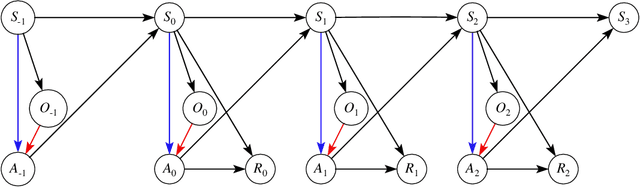
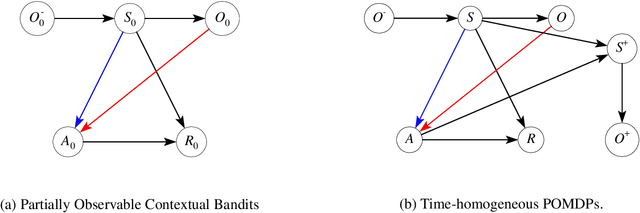
We consider off-policy evaluation (OPE) in Partially Observable Markov Decision Processes (POMDPs), where the evaluation policy depends only on observable variables and the behavior policy depends on unobservable latent variables. Existing works either assume no unmeasured confounders, or focus on settings where both the observation and the state spaces are tabular. As such, these methods suffer from either a large bias in the presence of unmeasured confounders, or a large variance in settings with continuous or large observation/state spaces. In this work, we first propose novel identification methods for OPE in POMDPs with latent confounders, by introducing bridge functions that link the target policy's value and the observed data distribution. In fully-observable MDPs, these bridge functions reduce to the familiar value functions and marginal density ratios between the evaluation and the behavior policies. We next propose minimax estimation methods for learning these bridge functions. Our proposal permits general function approximation and is thus applicable to settings with continuous or large observation/state spaces. Finally, we construct three estimators based on these estimated bridge functions, corresponding to a value function-based estimator, a marginalized importance sampling estimator, and a doubly-robust estimator. Their nonasymptotic and asymptotic properties are investigated in detail.