 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePESTO: Switching Point based Dynamic and Relative Positional Encoding for Code-Mixed Languages
Paper and Code
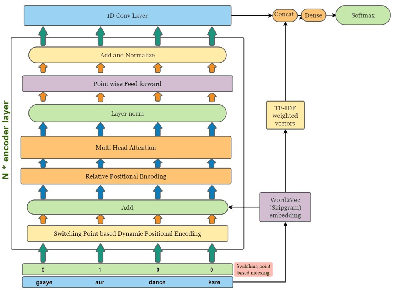
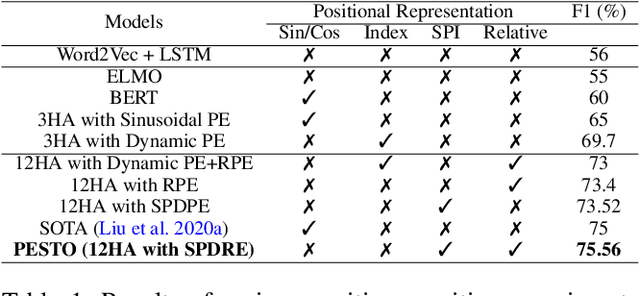
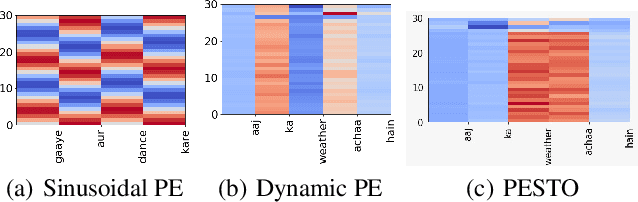
NLP applications for code-mixed (CM) or mix-lingual text have gained a significant momentum recently, the main reason being the prevalence of language mixing in social media communications in multi-lingual societies like India, Mexico, Europe, parts of USA etc. Word embeddings are basic build-ing blocks of any NLP system today, yet, word embedding for CM languages is an unexplored territory. The major bottleneck for CM word embeddings is switching points, where the language switches. These locations lack in contextually and statistical systems fail to model this phenomena due to high variance in the seen examples. In this paper we present our initial observations on applying switching point based positional encoding techniques for CM language, specifically Hinglish (Hindi - English). Results are only marginally better than SOTA, but it is evident that positional encoding could bean effective way to train position sensitive language models for CM text.