 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProposing an Interactive Audit Pipeline for Visual Privacy Research
Paper and Code
Nov 24, 2021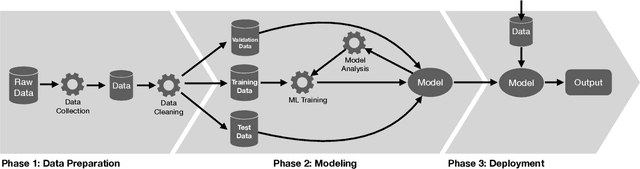
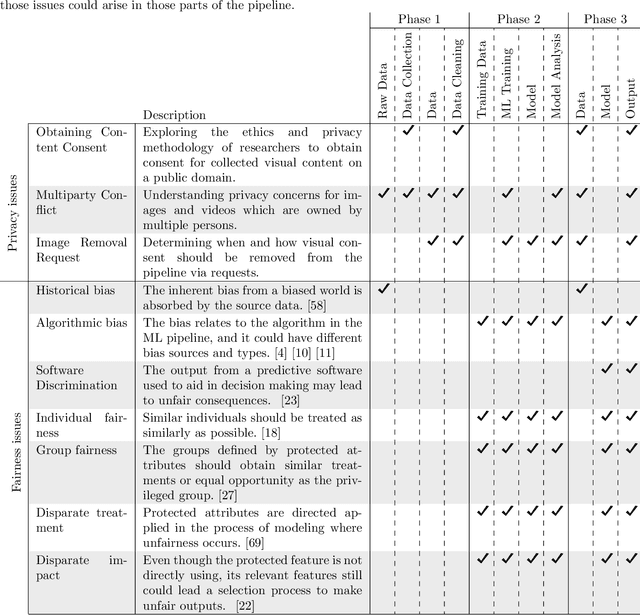
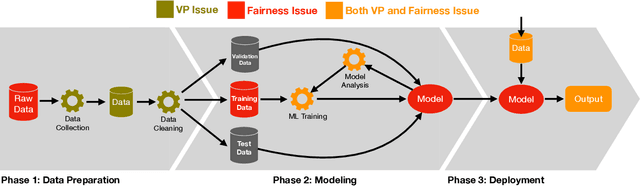
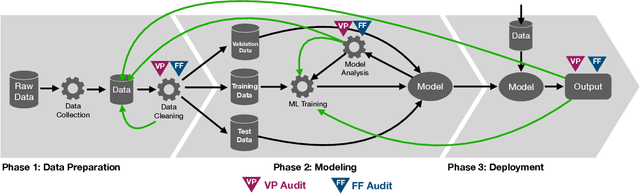
In an ideal world, deployed machine learning models will enhance our society. We hope that those models will provide unbiased and ethical decisions that will benefit everyone. However, this is not always the case; issues arise during the data preparation process throughout the steps leading to the models' deployment. The continued use of biased datasets and processes will adversely damage communities and increase the cost of fixing the problem later. In this work, we walk through the decision-making process that a researcher should consider before, during, and after a system deployment to understand the broader impacts of their research in the community. Throughout this paper, we discuss fairness, privacy, and ownership issues in the machine learning pipeline; we assert the need for a responsible human-over-the-loop methodology to bring accountability into the machine learning pipeline, and finally, reflect on the need to explore research agendas that have harmful societal impacts. We examine visual privacy research and draw lessons that can apply broadly to artificial intelligence. Our goal is to systematically analyze the machine learning pipeline for visual privacy and bias issues. We hope to raise stakeholder (e.g., researchers, modelers, corporations) awareness as these issues propagate in this pipeline's various machine learning phases.