 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Communication-Efficient Federated Multi-Armed Bandits
Paper and Code
Nov 02, 2021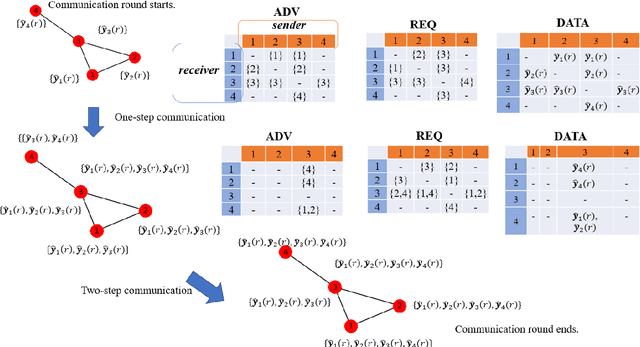
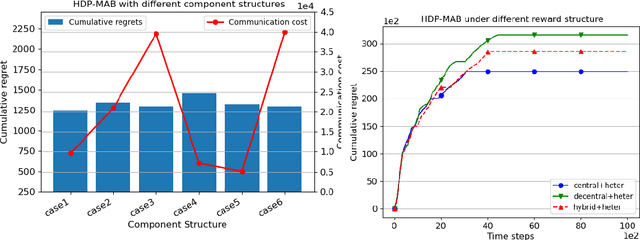
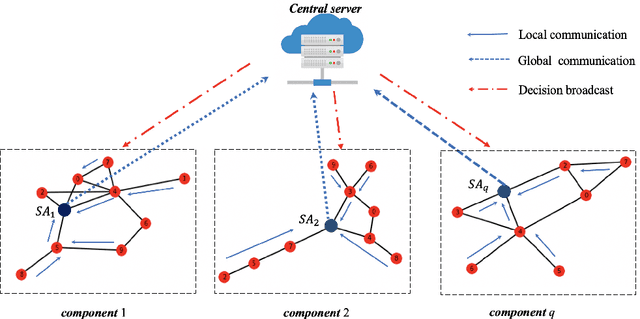
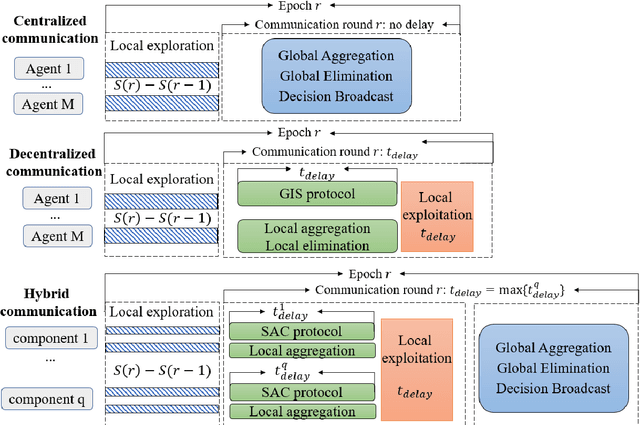
Communication bottleneck and data privacy are two critical concerns in federated multi-armed bandit (MAB) problems, such as situations in decision-making and recommendations of connected vehicles via wireless. In this paper, we design the privacy-preserving communication-efficient algorithm in such problems and study the interactions among privacy, communication and learning performance in terms of the regret. To be specific, we design privacy-preserving learning algorithms and communication protocols and derive the learning regret when networked private agents are performing online bandit learning in a master-worker, a decentralized and a hybrid structure. Our bandit learning algorithms are based on epoch-wise sub-optimal arm eliminations at each agent and agents exchange learning knowledge with the server/each other at the end of each epoch. Furthermore, we adopt the differential privacy (DP) approach to protect the data privacy at each agent when exchanging information; and we curtail communication costs by making less frequent communications with fewer agents participation. By analyzing the regret of our proposed algorithmic framework in the master-worker, decentralized and hybrid structures, we theoretically show tradeoffs between regret and communication costs/privacy. Finally, we empirically show these trade-offs which are consistent with our theoretical analysis.