 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Study of Long Document Classification
Paper and Code
Nov 01, 2021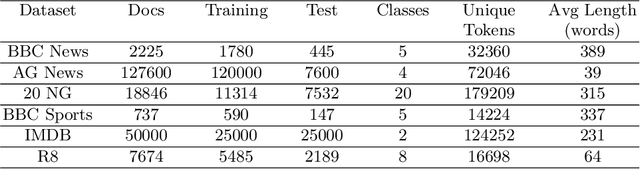
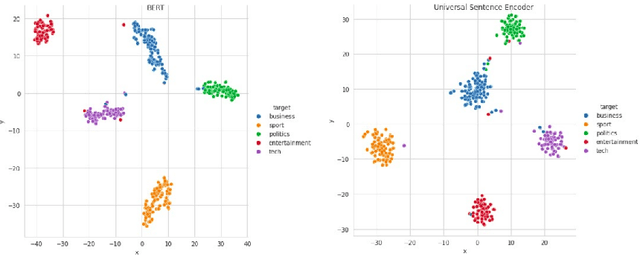
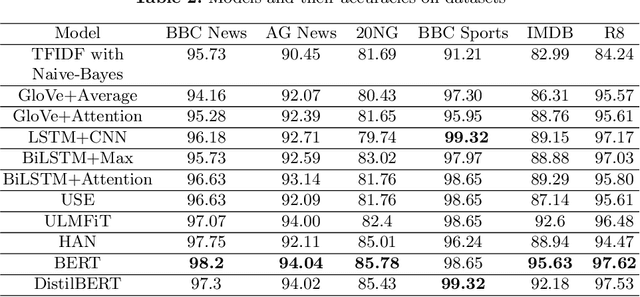
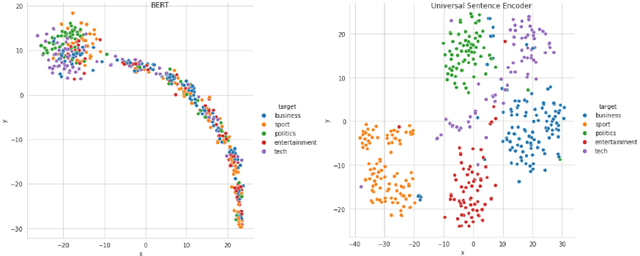
The amount of information stored in the form of documents on the internet has been increasing rapidly. Thus it has become a necessity to organize and maintain these documents in an optimum manner. Text classification algorithms study the complex relationships between words in a text and try to interpret the semantics of the document. These algorithms have evolved significantly in the past few years. There has been a lot of progress from simple machine learning algorithms to transformer-based architectures. However, existing literature has analyzed different approaches on different data sets thus making it difficult to compare the performance of machine learning algorithms. In this work, we revisit long document classification using standard machine learning approaches. We benchmark approaches ranging from simple Naive Bayes to complex BERT on six standard text classification datasets. We present an exhaustive comparison of different algorithms on a range of long document datasets. We re-iterate that long document classification is a simpler task and even basic algorithms perform competitively with BERT-based approaches on most of the datasets. The BERT-based models perform consistently well on all the datasets and can be blindly used for the document classification task when the computations cost is not a concern. In the shallow model's category, we suggest the usage of raw BiLSTM + Max architecture which performs decently across all the datasets. Even simpler Glove + Attention bag of words model can be utilized for simpler use cases. The importance of using sophisticated models is clearly visible in the IMDB sentiment dataset which is a comparatively harder task.