 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePnPOOD : Out-Of-Distribution Detection for Text Classification via Plug andPlay Data Augmentation
Paper and Code
Oct 31, 2021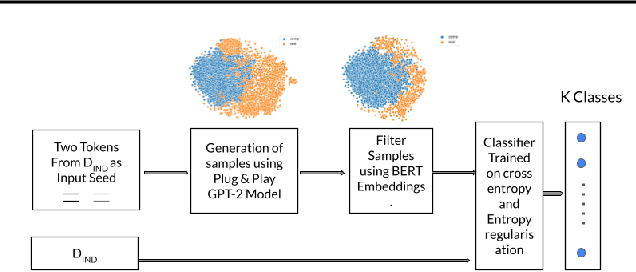
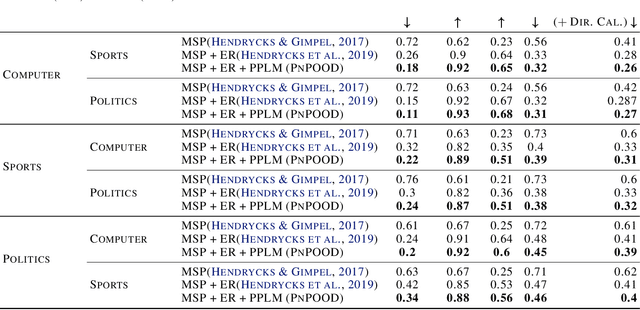
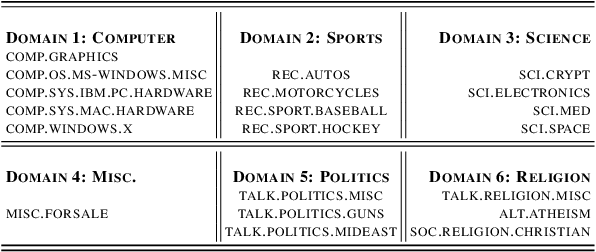
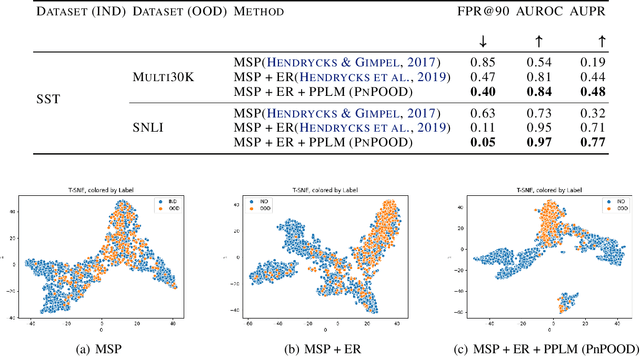
While Out-of-distribution (OOD) detection has been well explored in computer vision, there have been relatively few prior attempts in OOD detection for NLP classification. In this paper we argue that these prior attempts do not fully address the OOD problem and may suffer from data leakage and poor calibration of the resulting models. We present PnPOOD, a data augmentation technique to perform OOD detection via out-of-domain sample generation using the recently proposed Plug and Play Language Model (Dathathri et al., 2020). Our method generates high quality discriminative samples close to the class boundaries, resulting in accurate OOD detection at test time. We demonstrate that our model outperforms prior models on OOD sample detection, and exhibits lower calibration error on the 20 newsgroup text and Stanford Sentiment Treebank dataset (Lang, 1995; Socheret al., 2013). We further highlight an important data leakage issue with datasets used in prior attempts at OOD detection, and share results on a new dataset for OOD detection that does not suffer from the same problem.