 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Hyperparameter-free Policy Selection for Offline Reinforcement Learning
Paper and Code
Nov 02, 2021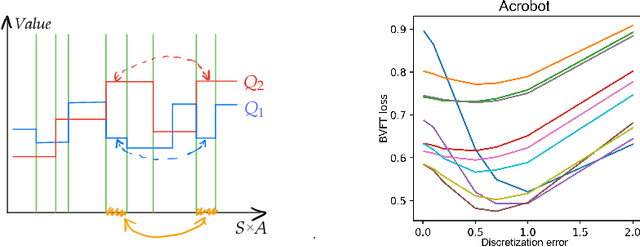
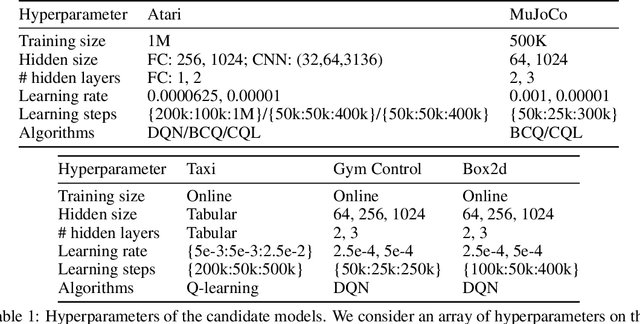
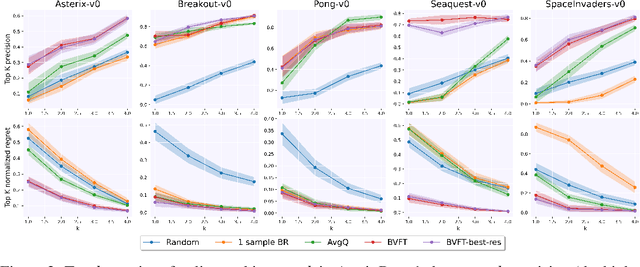
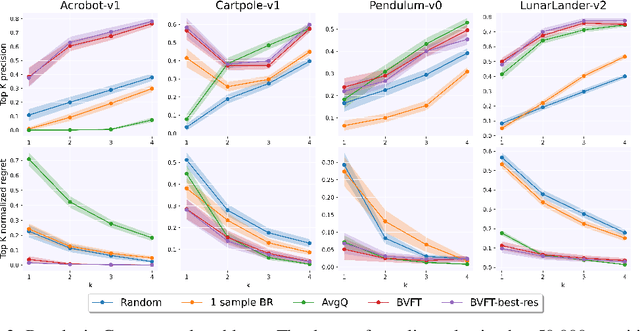
How to select between policies and value functions produced by different training algorithms in offline reinforcement learning (RL) -- which is crucial for hyperpa-rameter tuning -- is an important open question. Existing approaches based on off-policy evaluation (OPE) often require additional function approximation and hence hyperparameters, creating a chicken-and-egg situation. In this paper, we design hyperparameter-free algorithms for policy selection based on BVFT [XJ21], a recent theoretical advance in value-function selection, and demonstrate their effectiveness in discrete-action benchmarks such as Atari. To address performance degradation due to poor critics in continuous-action domains, we further combine BVFT with OPE to get the best of both worlds, and obtain a hyperparameter-tuning method for Q-function based OPE with theoretical guarantees as a side product.