 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHate and Offensive Speech Detection in Hindi and Marathi
Paper and Code
Nov 01, 2021
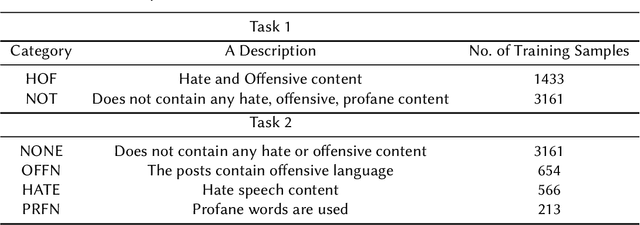
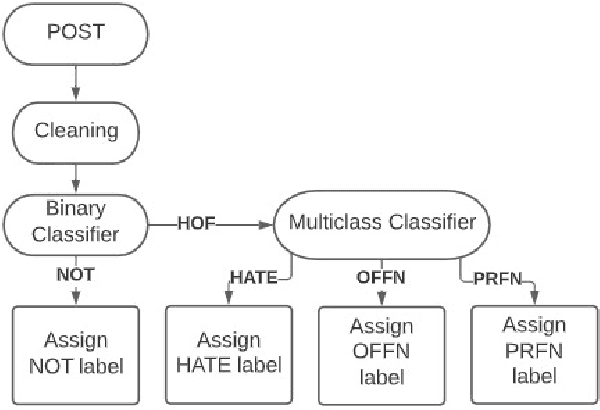
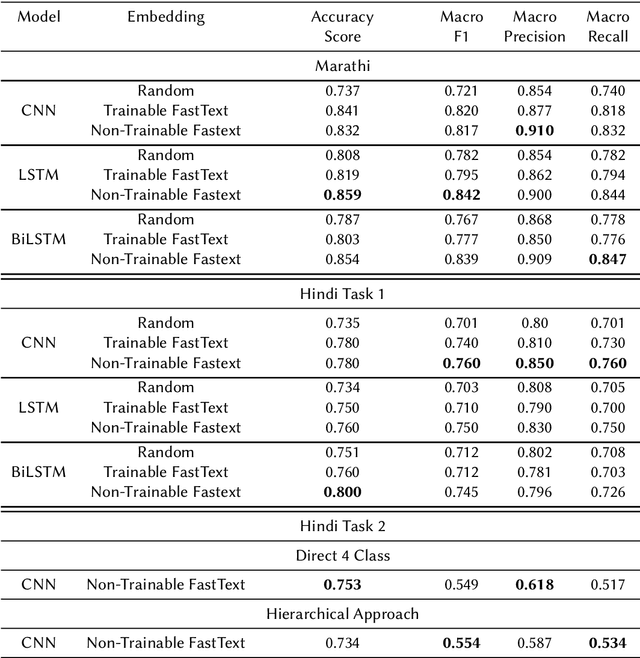
Sentiment analysis is the most basic NLP task to determine the polarity of text data. There has been a significant amount of work in the area of multilingual text as well. Still hate and offensive speech detection faces a challenge due to inadequate availability of data, especially for Indian languages like Hindi and Marathi. In this work, we consider hate and offensive speech detection in Hindi and Marathi texts. The problem is formulated as a text classification task using the state of the art deep learning approaches. We explore different deep learning architectures like CNN, LSTM, and variations of BERT like multilingual BERT, IndicBERT, and monolingual RoBERTa. The basic models based on CNN and LSTM are augmented with fast text word embeddings. We use the HASOC 2021 Hindi and Marathi hate speech datasets to compare these algorithms. The Marathi dataset consists of binary labels and the Hindi dataset consists of binary as well as more-fine grained labels. We show that the transformer-based models perform the best and even the basic models along with FastText embeddings give a competitive performance. Moreover, with normal hyper-parameter tuning, the basic models perform better than BERT-based models on the fine-grained Hindi dataset.