 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEET! Tunisian Dataset for Toxic Speech Detection
Paper and Code
Oct 11, 2021
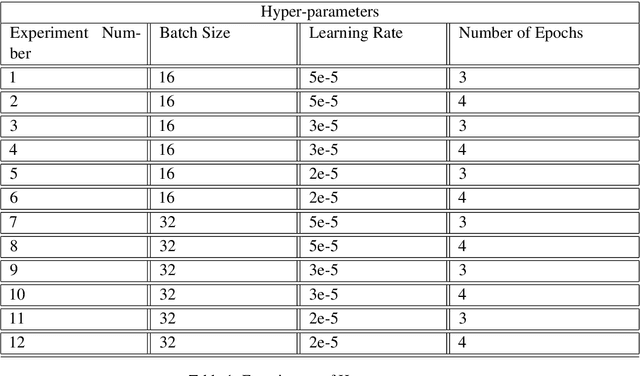
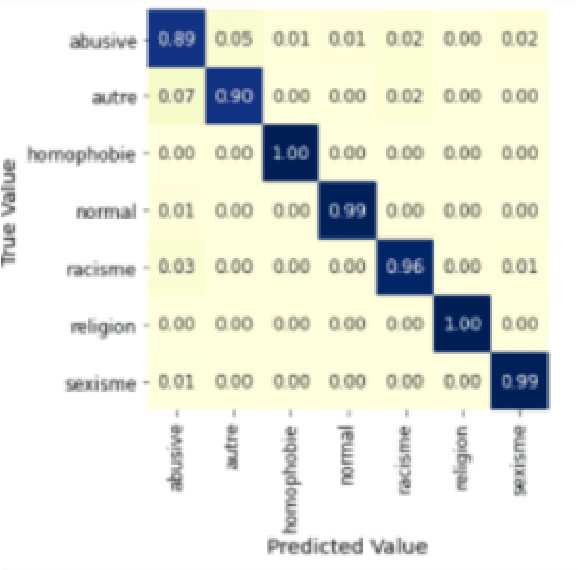
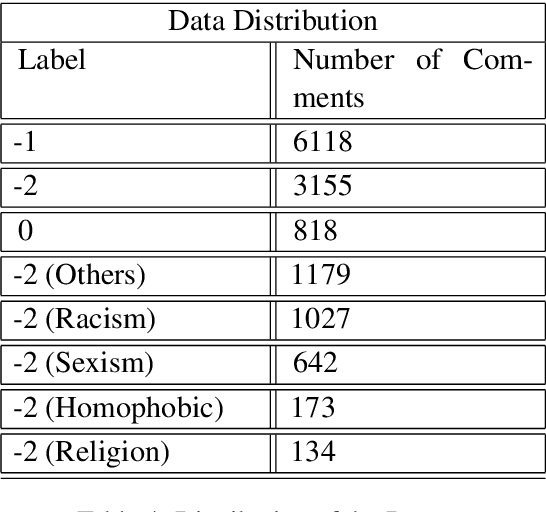
The complete freedom of expression in social media has its costs especially in spreading harmful and abusive content that may induce people to act accordingly. Therefore, the need of detecting automatically such a content becomes an urgent task that will help and enhance the efficiency in limiting this toxic spread. Compared to other Arabic dialects which are mostly based on MSA, the Tunisian dialect is a combination of many other languages like MSA, Tamazight, Italian and French. Because of its rich language, dealing with NLP problems can be challenging due to the lack of large annotated datasets. In this paper we are introducing a new annotated dataset composed of approximately 10k of comments. We provide an in-depth exploration of its vocabulary through feature engineering approaches as well as the results of the classification performance of machine learning classifiers like NB and SVM and deep learning models such as ARBERT, MARBERT and XLM-R.