 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTBCOV: Two Billion Multilingual COVID-19 Tweets with Sentiment, Entity, Geo, and Gender Labels
Paper and Code
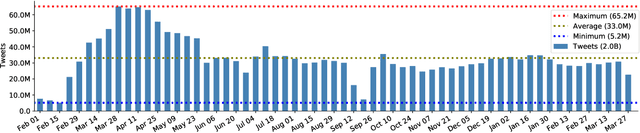

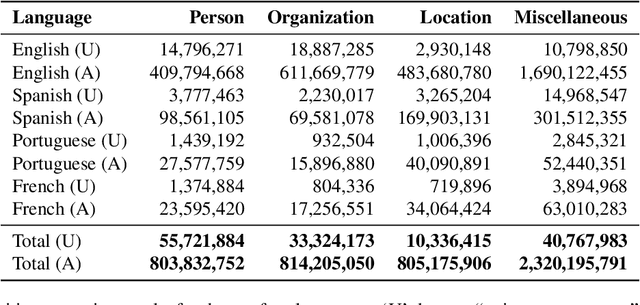

The widespread usage of social networks during mass convergence events, such as health emergencies and disease outbreaks, provides instant access to citizen-generated data that carry rich information about public opinions, sentiments, urgent needs, and situational reports. Such information can help authorities understand the emergent situation and react accordingly. Moreover, social media plays a vital role in tackling misinformation and disinformation. This work presents TBCOV, a large-scale Twitter dataset comprising more than two billion multilingual tweets related to the COVID-19 pandemic collected worldwide over a continuous period of more than one year. More importantly, several state-of-the-art deep learning models are used to enrich the data with important attributes, including sentiment labels, named-entities (e.g., mentions of persons, organizations, locations), user types, and gender information. Last but not least, a geotagging method is proposed to assign country, state, county, and city information to tweets, enabling a myriad of data analysis tasks to understand real-world issues. Our sentiment and trend analyses reveal interesting insights and confirm TBCOV's broad coverage of important topics.