 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoogle Neural Network Models for Edge Devices: Analyzing and Mitigating Machine Learning Inference Bottlenecks
Paper and Code
Sep 29, 2021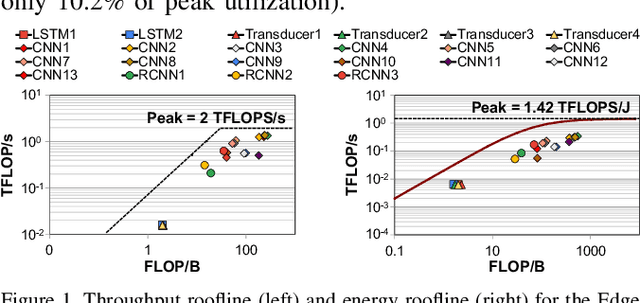
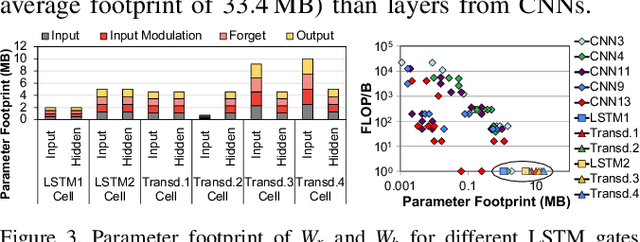
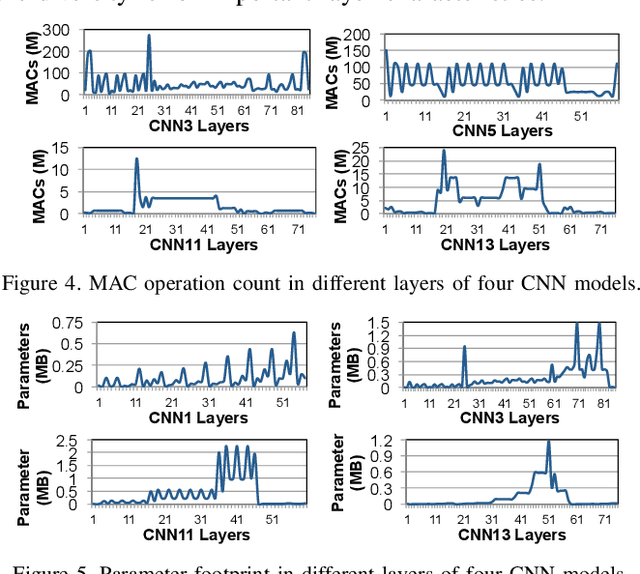
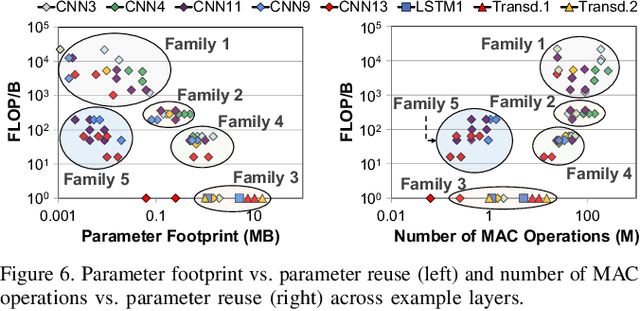
Emerging edge computing platforms often contain machine learning (ML) accelerators that can accelerate inference for a wide range of neural network (NN) models. These models are designed to fit within the limited area and energy constraints of the edge computing platforms, each targeting various applications (e.g., face detection, speech recognition, translation, image captioning, video analytics). To understand how edge ML accelerators perform, we characterize the performance of a commercial Google Edge TPU, using 24 Google edge NN models (which span a wide range of NN model types) and analyzing each NN layer within each model. We find that the Edge TPU suffers from three major shortcomings: (1) it operates significantly below peak computational throughput, (2) it operates significantly below its theoretical energy efficiency, and (3) its memory system is a large energy and performance bottleneck. Our characterization reveals that the one-size-fits-all, monolithic design of the Edge TPU ignores the high degree of heterogeneity both across different NN models and across different NN layers within the same NN model, leading to the shortcomings we observe. We propose a new acceleration framework called Mensa. Mensa incorporates multiple heterogeneous edge ML accelerators (including both on-chip and near-data accelerators), each of which caters to the characteristics of a particular subset of NN models and layers. During NN inference, for each NN layer, Mensa decides which accelerator to schedule the layer on, taking into account both the optimality of each accelerator for the layer and layer-to-layer communication costs. Averaged across all 24 Google edge NN models, Mensa improves energy efficiency and throughput by 3.0x and 3.1x over the Edge TPU, and by 2.4x and 4.3x over Eyeriss~v2, a state-of-the-art accelerator.