 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Transformers for Job Expression Extraction and Classification in a Low-Resource Setting
Paper and Code
Sep 17, 2021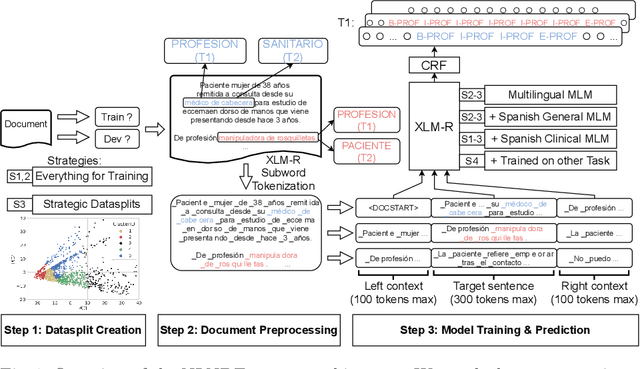
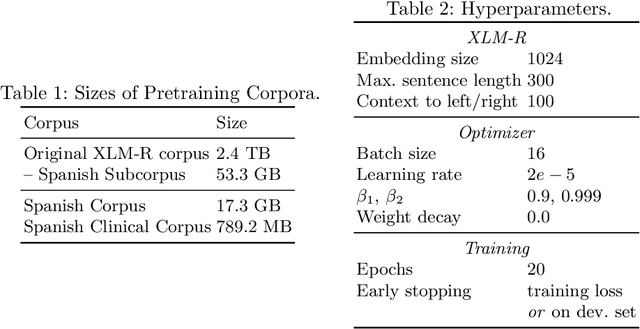
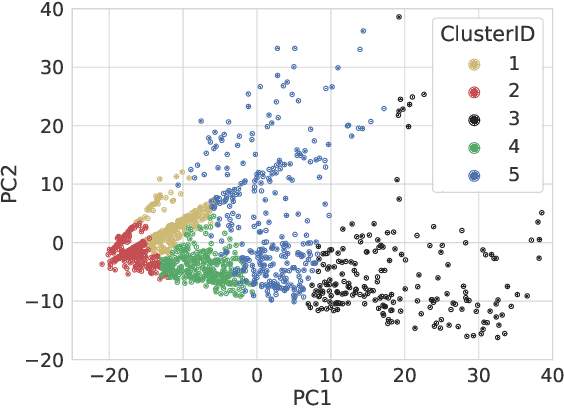
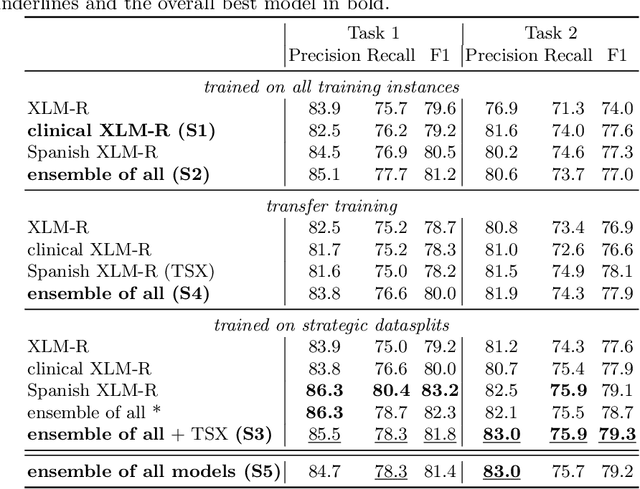
In this paper, we explore possible improvements of transformer models in a low-resource setting. In particular, we present our approaches to tackle the first two of three subtasks of the MEDDOPROF competition, i.e., the extraction and classification of job expressions in Spanish clinical texts. As neither language nor domain experts, we experiment with the multilingual XLM-R transformer model and tackle these low-resource information extraction tasks as sequence-labeling problems. We explore domain- and language-adaptive pretraining, transfer learning and strategic datasplits to boost the transformer model. Our results show strong improvements using these methods by up to 5.3 F1 points compared to a fine-tuned XLM-R model. Our best models achieve 83.2 and 79.3 F1 for the first two tasks, respectively.