 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-training with Few-shot Rationalization: Teacher Explanations Aid Student in Few-shot NLU
Paper and Code
Sep 17, 2021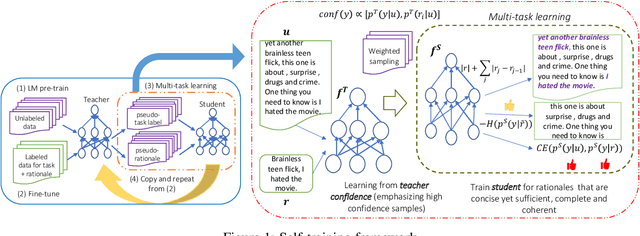
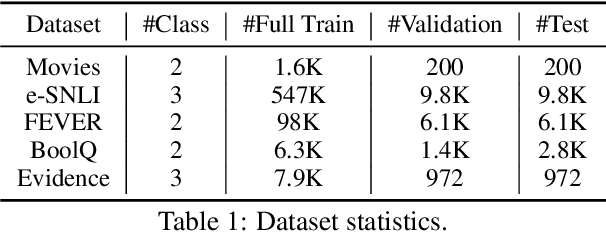
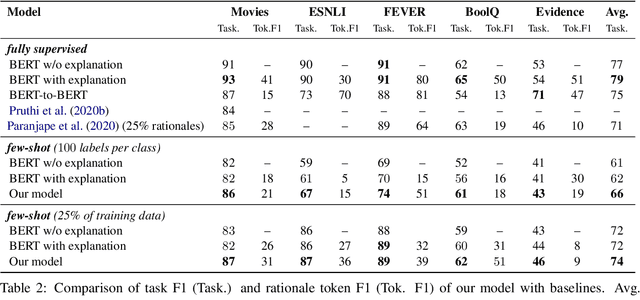

While pre-trained language models have obtained state-of-the-art performance for several natural language understanding tasks, they are quite opaque in terms of their decision-making process. While some recent works focus on rationalizing neural predictions by highlighting salient concepts in the text as justifications or rationales, they rely on thousands of labeled training examples for both task labels as well as an-notated rationales for every instance. Such extensive large-scale annotations are infeasible to obtain for many tasks. To this end, we develop a multi-task teacher-student framework based on self-training language models with limited task-specific labels and rationales, and judicious sample selection to learn from informative pseudo-labeled examples1. We study several characteristics of what constitutes a good rationale and demonstrate that the neural model performance can be significantly improved by making it aware of its rationalized predictions, particularly in low-resource settings. Extensive experiments in several bench-mark datasets demonstrate the effectiveness of our approach.