 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Open Information Extraction using Question Generation and Reading Comprehension
Paper and Code
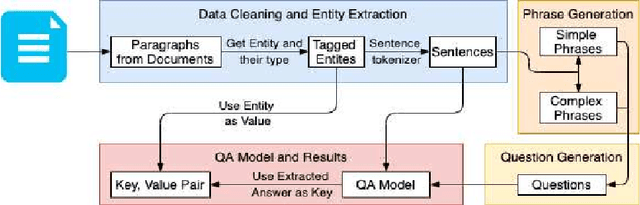
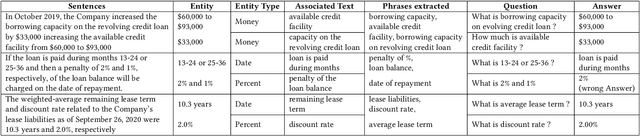
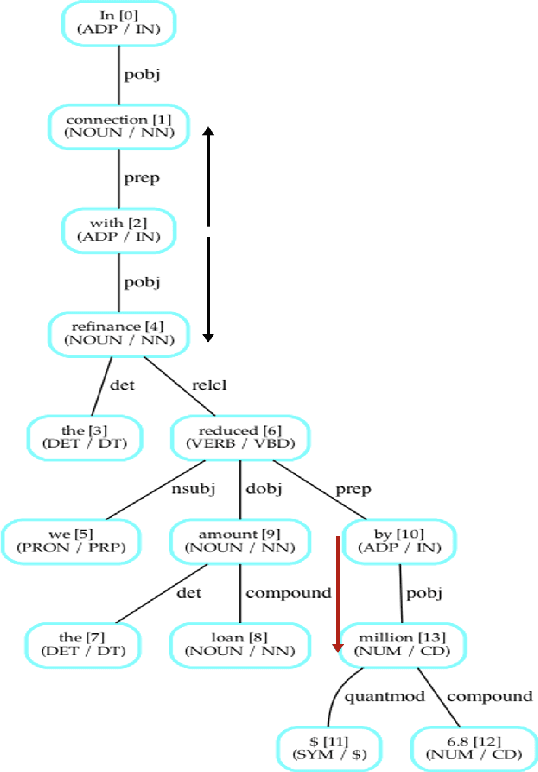
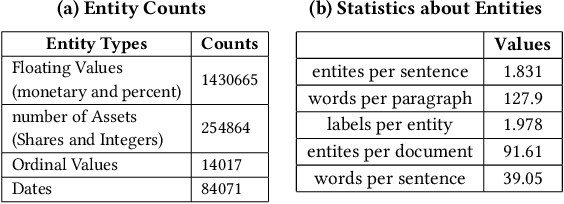
Typically, Open Information Extraction (OpenIE) focuses on extracting triples, representing a subject, a relation, and the object of the relation. However, most of the existing techniques are based on a predefined set of relations in each domain which limits their applicability to newer domains where these relations may be unknown such as financial documents. This paper presents a zero-shot open information extraction technique that extracts the entities (value) and their descriptions (key) from a sentence, using off the shelf machine reading comprehension (MRC) Model. The input questions to this model are created using a novel noun phrase generation method. This method takes the context of the sentence into account and can create a wide variety of questions making our technique domain independent. Given the questions and the sentence, our technique uses the MRC model to extract entities (value). The noun phrase corresponding to the question, with the highest confidence, is taken as the description (key). This paper also introduces the EDGAR10-Q dataset which is based on publicly available financial documents from corporations listed in US securities and exchange commission (SEC). The dataset consists of paragraphs, tagged values (entities), and their keys (descriptions) and is one of the largest among entity extraction datasets. This dataset will be a valuable addition to the research community, especially in the financial domain. Finally, the paper demonstrates the efficacy of the proposed technique on the EDGAR10-Q and Ade corpus drug dosage datasets, where it obtained 86.84 % and 97% accuracy, respectively.