Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForget me not: A Gentle Reminder to Mind the Simple Multi-Layer Perceptron Baseline for Text Classification
Paper and Code
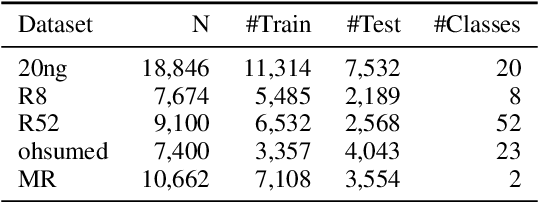
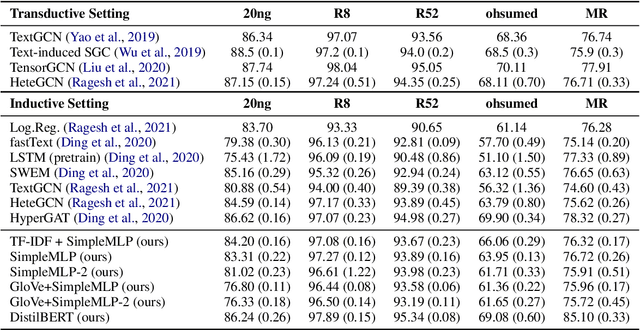
Graph neural networks have triggered a resurgence of graph-based text classification. We show that already a simple MLP baseline achieves comparable performance on benchmark datasets, questioning the importance of synthetic graph structures. When considering an inductive scenario, i. e., when adding new documents to a corpus, a simple MLP even outperforms the recent graph-based models TextGCN and HeteGCN and is comparable with HyperGAT. We further fine-tune DistilBERT and find that it outperforms all state-of-the-art models. We suggest that future studies use at least an MLP baseline to contextualize the results. We provide recommendations for the design and training of such a baseline.
* 5 pages, added link to code
View paper on